✅ In-Context Learning
☑️ Fine Tuning과의 차이점
✔️ Fine Tuning
• 대규모 코퍼스로 사전학습 후,
• 적은 규모의 specific한 데이터셋에 대해 fine tuning하는 과정
=> 일반화된 task가 아닌, 일부 task에 대해서 능력을 집중적으로 향상
Finetuning LLMs Efficiently with Adapters

✔️ Fine Tuning vs In-Context Learning-Context Learning
LLM (Large Language Model)의 현재와 미래 – 테스트웍스

✔️ Fine Tuning vs In-Context Learning

☑️ N-Shot Learning
✔️ In-Context Learning
•원하는 task에 대한 간단한 설명을 함께 Input
=> 학습 과정에서 다양한 스킬과 패턴인식 능력을 키워, Inference 단계에서 원하는 task에 빠르게 적응할 수 있도록 함

✔️ Zero-Shot Learning
•예시를 전혀 보지 않고 모델 업데이트 없이 새로운 태스크를 수행
• Unsupervised multitask learners
•독해, 번역, 요약, Q&A 등에 대해 zero-shot 능력이 꽤 있음!
=> Zero-shot인데도 특정 태스크는 기존의 SOTA* 모델들을 짓눌러버림

✔️ One-Shot Learning
•단 한 개의 예시와, task에 대한 자연어 지시문이 제공
•이 방법이 사람이 소통하는 방법과 가장 흡사한 방법
One-Shot Learning in AI - Definition and Examples | Encord

✔️ Few-Shot Learning
•모델은 추론 시 단 몇 개의 예시만을 참고해서 정답을 생성
•문맥과 원하는 답의 예시들이 주어짐. 이후 마지막으로 단 한 개의 문맥이 주어지면, 모델은 답을 생성해야 함
• Task-specific한 데이터에 대한 필요를 크게 줄여줌(즉, 몇 개 없어도 됨)
=> 새로운 task에 효율적으로 빠르게 적응

✔️ 모델에 주어지는 예시의 수가 증가할수록 성능이 증가

✔️ In-Context Prompt는 중요

✅ How to build ChatGPT?
☑️ ChatGPT란?
✔️ ChatGPT
•무의식적인 데이터 생성이 아닌, 모델에게 피드백을 주기 위한 데이터 생성
•사람의 지시를 반영하는 “Instruction Tuning”과 피드백을 반영하는 “Reinforcement Learning”으로 구성
✔️ 5일만에 사용자수 100만명 돌파
Chart: Threads Shoots Past One Million User Mark at Lightning Speed | Statista


✔️ 생산성 향상
ChatGPT Lifts Business Professionals’ Productivity and Improves Work Quality

✔️ ChatGPT의 활용
132. ChatGPT 톺아보기 (전자통신부설연구소 고우영 선임연구원) - YouTube ChatGPT, 기회인가 위협인가
✔️ ChatGPT와 PLM의 연계
[칼럼] 챗GPT-PLM 활용의 모습 - 캐드앤그래픽스

✔️ 기존 Chatbot의 경우, 적어도 4-5개이상의 AI모델들의 조합으로 구성
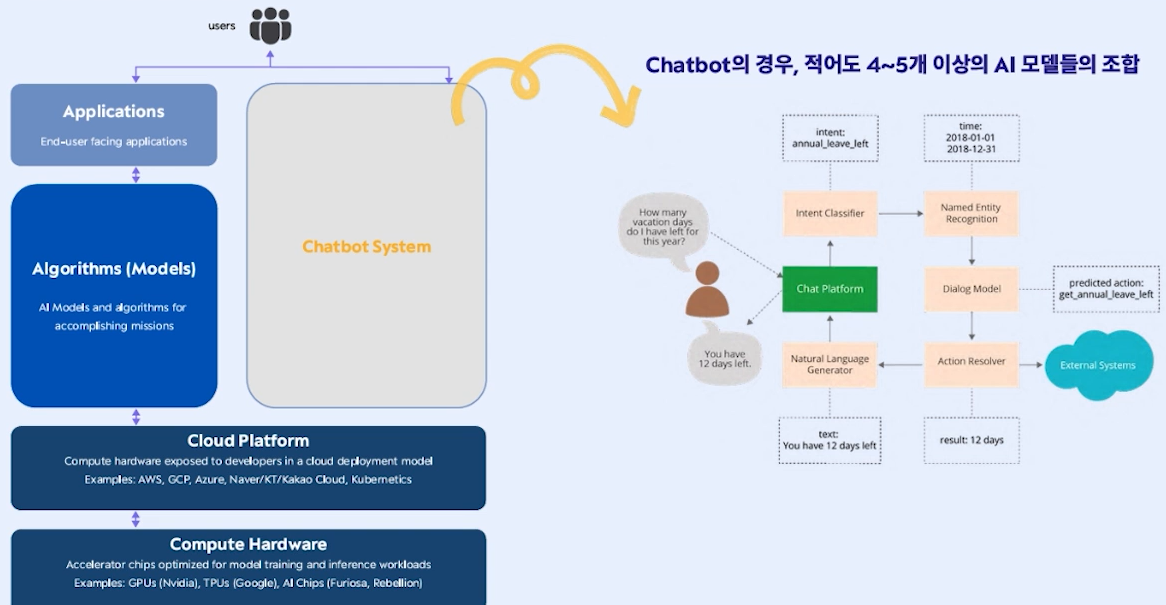
✔️ Multi-Tasking
• ChatGPT는 chatbot에서 요구한 태스크를 하나의 모델로 수행 가능이 외에도 훨씬 많은 태스크를 수행 가능
•하나의 모델이지만, 하나의 서비스로도 볼 수 있음 ( LLM as a Service)
•멀티태스킹, 학습 뿐만 아니라 추론 시에도 엄청난 Infra관련 투자/경험/기술이 필요
✔️ 어떤 태스크까지도 ChatGPT가 잘할까?
• ChatGPT API를 활용한 수많은 서비스들이 많이 나올 것이라 기대
=> ChatGPT의 역량 분석 필요 (Prompt Discovering)
✔️ ChatGPT Plugin

다양한 외부플러그인을 연동하여 범위를 확장 !
✔️ 그래서.. ChatGPT란?
• GPT-3.5를 파인튜닝한 모델
• InstructGPT의 "sibling model"로, 학습 방식이 유사
• Demonstration data: 데이터를 대화형으로 바꿈 •
보상 모델(Reward model, RM): 유저의 선호도에 대한 모델
• 보상 모델을 활용해 ChatGPT를 강화학습(Reinforcement learning, RL)으로 업데이트
✔️ 그래서.. ChatGPT란?

✔️ Supervised Fine Tuning + RLHF
Understanding and Using Supervised Fine-Tuning (SFT) for Language Models

☑️ ChatGPT의 학습방법
✔️ 기존 GPT 모델에게 명령을 한다면?
[논문리뷰] GPT3의 새로워진 버전 - InstructGPT : 인간의 지시에 따른 결과물을 완성해내는 AI

✔️ Instruction Tuning
•일반적인 언어모델은 다음 토큰을 예측하거나, 일부 태스크를 수행하는 것에 초점을 맞추어 학습
=> 사람의 지시에 따르지 못함
• Instruction Tuning은 사람의 명령(Instruction)을 따르도록, 요구를 수행하도록 모델을 Fine Tuning하는 방식
•명령에 대한 파인튜닝과 강화학습을 하면 사용자의 의도를 더 잘 파악하고 답변한다는 것에 착안한 InstructGPT(2022년 1월)의 실험 방식을 가미
Notion – The all-in-one workspace for your notes, tasks, wikis, and databases.

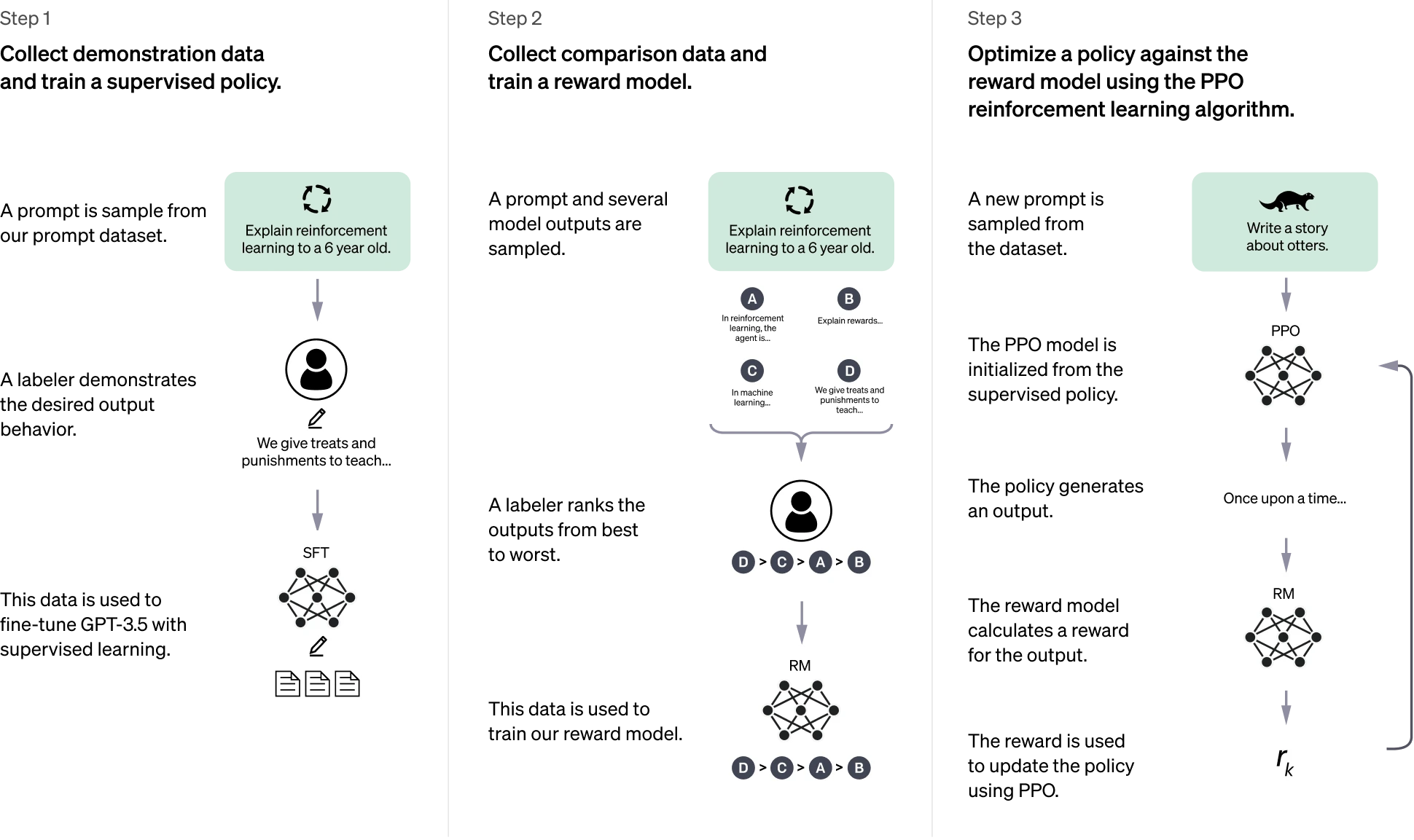
✔️ Step 1. SFT(Supervised Fine Tuning)
• 예제 데이터 수집 후 supervised policy를 학습 => SFT 모델 확보
: GPT가 주어진 지시문대로 행동하도록 가르치기 위해, 해당 데이터셋을 만들어 fine tuning
• 이를 위해 지시 프롬프트와 그에 대한 결과물로 이루어진 데이터셋을 정의
(demonstration dataset, 13K prompts)
- 프롬프트 데이터셋으로부터 지시 prompt를 샘플링 (예) 8살 아이에게 달착륙을 설명해보시오
- 라벨러는 프롬프트에 적합한 행동을 예시로 라벨링 (예) 몇몇 사람들이 달에 갔답니다 ~~
• 이 데이터셋을 GPT-3에 대해 Fine-tuning => SFT (supervised fine-tuning) 모델
- 지시문을 따르는 점에 있어 이 모델은 이미 GPT-3보다 성능이 우수했지만, 완벽하게 원하는 방식으로 작동하지는 않음
✔️ Step 2. 결과물에 대한 사람의 선호도 데이터를 학습
• Reward Model 학습 : SFT로 생성된 결과물에 대해 사람의 선호도를 반영할 수 있는 Reward Model 학습]
• Comparison dataset은 33K 개의 프롬프트로 이루어져 있으며 이를 Reward Model 학습에 적합하게 구성
- Comparison dataset은 프롬프트와 그에 따른 결과물들 (4-9개), 그리고 그 결과에 대한 선호도 순위로 구성됨
- 즉, 프롬프트가 주어질 때 Reward Model은 결과물들에 대해 사람의 선호도를 예측하는 방법을 학습
Improving your LLMs with RLHF on Amazon SageMaker | AWS Machine Learning Blog

✔️ Step 3. RLHF

• 강화학습을 사용해 Reward Model에 대해 policy를 최적화 : Step1의 SFT 모델을 Step2의 보상모델을 사용해 강화학습을 통해 추가 fine-tuning
• Proximal policy optimization algorithm(PPO) - Reward Model을 보상함수로 사용하여 정책을 최적화 (InstructGPT가 사람의 피드백을 얻는 방법)
✔️ PPO를 통해 Reward Model의 Policy를 반영
• PPO를 통한 fine-tuning 과정
1) GPT는 프롬프트를 보고, 그에 대한 결과 문장들을 생성
2) 생성된 문장들을 Reward Model이 평가하여 reward(보상)를 계산
3) 보상 값이 GPT에게 주어지고 모델은 보상을 최대화하는 방향, 즉 사람이 원하는 문장을 생성하는 방향으로 정책을 업데이트
=> 사람의 지시에 따르면서, 유용하고 안전한 문장을 생성하도록 최적화

✔️ 결국 ChatGPT는..
•먼저 지시문에 따라 결과를 완성하는 초기 모델, SFT 모델을 완성한 후
•사람의 feedback을 모사하는 보상 모델(Reward model)을 확보하여
•이를 통해 SFT 모델이 사람이 더 선호하는 결과를 추론하도록 강화학습을 진행한 것!
2025년 1월 최저가보장 한정판매 고양이 운전_가로형
✔️ 세상에 있는 책은 다 읽었으며 50개+ 언어 구사자 그런데 가물가물
✔️ Persona Injection
성격을 먼저 정의 하고 대화를 하면 더 좋아짐
✔️ ChatGPT의 올바른 사용법: 프롬프트 구성

✔️ 짧고. 간결하고. 확실하게

✔️ 출력물도 형태 지정
✔️ 길어지면 구역 지정

✔️ 복잡하면 구역 지정
✔️ 예시 들기

✔️ 3Cs Framework

✅ Parameter Efficient Fine Tuning
☑️ PEFT 소개
✔️ Full fine tuning of LLMs is challenging
PEFT — Parameter Efficient Fine Tuning | by kanika adik | Medium

✔️ Why PEFT?
•모델이 점점 커짐에 따라 시판 그래픽카드로 모델 전체를 fine tuning하는 것은 불가능
•또한 fine tuning된 모델은 이전의 사전학습된 모델과 똑같은 크기. 파인튜닝된 모델을 저장하고 사용하는 것 또한 (시간, 경제적으로) 비용이 많이 드는 일
=> PEFT(parameter-efficient fine tuning)은 이 두 가지의 문제를 해결하고자 등장
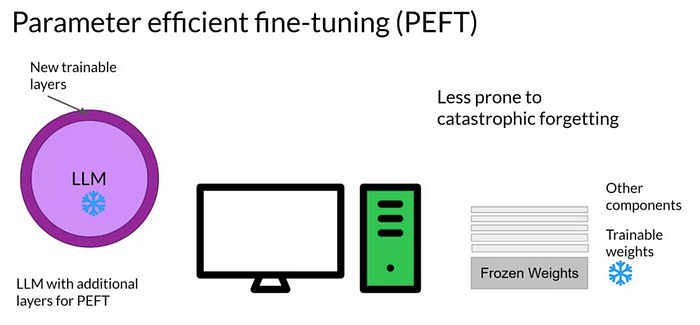
✔️ Parameter Efficient Fine Tuning (PEFT)
•사전 훈련된 언어 모델을 특정 작업이나 상황에 적용할 때, 가중치의 일부만 업데이트하는 파인 튜닝 방법
•일부만 fine tuning하므로 연산량이 대폭 감소
• Fine tuning 할 때 발생하는 문제점 중 하나인 catastrophic forgetting 완화 (일부가중치만 업데이트)
• PEFT는 또한 적은 데이터에서 fine tuning 할 때나 도메인 밖의 데이터를 일반화할 때 더욱 좋은 성능
=> 적은 수의 파라미터를 학습하는 것만으로 모델 전체를 fine tuning 하는 것과 유사한 효과
✔️ PEFT의 장점
PEFT of LLMs: A Practical Guide

✔️ PEFT 프로세스

☑️ PEFT 방법론
✔️ Pretrain, Prompt, Predict: A New Paradigm for NLP

✔️ Prompt란?
•일반적인 정의 : 프롬프트라는 것은 언어모델에 전달하는 질문이나 요청을 사용자가 응답을 유도한다는 의미
• Template을 사람이 문자 그대로 해석할 수 있는지에 따라 구분
: Discrete Prompts(= Hard Prompt) 실제 입력어로 넣는것들
: Continuous Prompts(= Soft Prompt) 실제 학습이 이뤄지는 프롬포트 (임베딩)
• 이러한 프롬프트(prompt)를 사용해 PLMs를 조정하는 방법
=> Prompt Learning

✔️ Prefix-Tuning
• 연속적인 태스크 특화 벡터(continuous task-specific vector = prefix) 를 활용해 언어모델을 최적화하는 방법
• LM 고정하고 각 layer의 input 앞에 task-specific vectors를 붙여 tuning함
• 각 Task에 대하여 parameter를 tuning 시켜 task 마다 적합한 task-specific vectors를 도출
=> 하나의 언어모델로 여러 개의 태스크를 처리할 수 있음 (prefix를 학습)
On Robust Prefix-Tuning for Text Classification – THUMT Research Blog

✔️ Prefix-Tuning vs Fine-Tuning
• Prefix-tuning은 각 Task에 대한 task-specific vectors(Prefix)를 계산하는 parameter만을 fine-tuning
=> 전체 모델을 fine-tuning 및 저장하는 방식에 비해 overhead 감소

✔️ Prefix-Tuning
• Table-to-text, summarization 등의 task에 대해 평가
• Prefix-Tuning 모델이 Fine-tuning, Adapter를 적용한 조건 보다 더 적은 파라미터를 학습하면서 더 높거나 유사한 성능을 달성

✔️ Prompt Tuning
•전체 파라미터를 튜닝하는 대신, 입력 프롬프트 임베딩만 학습하는 방법
=> 즉 모델에 입력되는 프롬프트에 해당하는 weight만을 학습
• PLMs를 freeze하고 입력 텍스트에 추가되는 downstream task당 k개의 토큰만을 학습함


✔️ Fine Tuning vs Prompt Tuning
Large Language Model을 밀어서 잠금해제: Parameter-Efficient Fine-Tuning 2 |

Prompt fine tuning 의 장점
1. 특정Task모델에 유연성을 크게 향상 시킬수 있다.
2. 학습에 필요한 파라미터 양이 대폭 감소한다. 학습과정이 빨리지고 계산비용이 낮아진다.
3. 이방식은 모델의 일반화 능력을 손상시키지 않으면서 특정 task에 대한 성능을 향상시킨다.
✔️ Prompt Tuning
• T5에 적용 시 GPT3 의 few-shot prompt design 보다 우수함
• Prompt Tuning 사용시, Domain Adaptation에 용이
=> 서로 다른 데이터로 학습, 평가 시에도 성능이 보존

✔️ P-Tuning
• PLMs의 전체 weight를 fine-tuning하지 않고, continuous prompt embeddings만 tuning하는 방법
• LM의 입력부에 Prompt Encoder(Bi-LSTM)를 두어 나온 출력 값을 Prompt의 Token Embedding으로 사용
• Task와 관련된 anchor tokens을 추가하여 성능 개선(anchor token값은 고정)
•언어모델의 구조와 상관없이 적용가능

• NLU Task에서 GPT style model로 BERT style model보다 더 낫거나 비슷한 성능
• P-tuning 방식을 적용하여 SuperGLUE 벤치마크 측정 결과: AE, AR 방식 모두 모든 세팅(fully-supervised & few-shot setting)에서 기존 fine-tuning 방식 대비 성능 개선. 특히 AR 방식의 성능 개선 폭이 더 크게 나타남

• Manual Prompt(MP), Fine-tuning(FT), MP+FT, P-tuning의 성능을 비교해보면 Fine tuning보다 같거나 더 좋은 결과
✔️ Prefix Tuning vs Prompt Tuning vs P-Tuning
Large Language Model을 밀어서 잠금해제: Parameter-Efficient Fine-Tuning 2 |

✔️ LoRA (Low Rank Adaptation)
• Pre-trained weigh를 고정한 상태로 유지하며, dense layer 변화에 대한 rank decomposition metrices를 최적화


• GPT-3의 경우 175B의 파라미터 가운데 0.01%의 파라미터 개수만 이용할 정도로 높은 효율성
•작은 rank 값을 설정해도 성능이 유지
✔️ How to use LoRA?
• Huggingface에서 제공하는 peft 라이브러리를 통해 쉽게 사용 가능

✔️ Quantization
• Training Time 을 줄이는게 아닌, Inference Time 을 줄이는 것이 주 목적
(모델을 서빙할때 많이 사용됨)
딥러닝의 Quantization (양자화)와 Quantization Aware Training - gaussian37

✔️ Quantization종류
모델 경량화 2 - Quantization(양자화) | aalphaca's devlog

포스트 트레이닝할때 / 학습과정할때
✔️ Quantization이란?
•모델의 파라미터를 lower bit로 표현함으로써 계산과 메모리 access 속도를 높이는 경량화 기법
•보통 32비트 부동소수점 연산을 8비트 정수로 변환하는 방식 사용
: Pytorch, Tensorflow의 default data type = fp32

✔️ 양자화와 분위수

✓ 주요목표 : 모델을 손상시키지 않으면서 모델의 성능높임
✓ 양자화 : 모델의 가중치와 활성화를 더 낮은 비트 정밀도로 변환해서 모델의 크기를 줄이고 실시간을
단축하고 에너지 효율성을 높이는 개념
✓ 연속적인 실수값을 미리 정의된 이산적인 심볼로 맵핑하는과정
✓ 큰 실수값의 집합을 더 작은 실수값의 집합으로 변환
✓ 분위수 : 실제 숫자의 분포를 기반으로 중요한 값을 보존
✓ 각 분위의 속하는 값들을 같은 값으로 맵핑 ( 중앙값과 최빈값을 잘 보존)
✔️ 신경망에 적용

✔️ QLoRA (Quantized Low Rank Adapters)
• Q + LoRA
: 4-bit Quantized language model into LoRA
=> 기존 사전학습 모델의 weight 는 양자화로 저장하고, LoRA에 의해 더해지는 weight는 그대로 16-bit finetuning을 유지
•사전학습 모델을 4-bit로 quantize하는 high-precision 방법
=> QLoRA를 사용하면 16-bit fine-tuning 성능을 유지하면서 단일 48GB GPU에서 650억 매개 변수 모델을 fine tuning 가능
•두 벤치마크 모두에서 16, 8, 4비트의 어댑터가 16비트 full-finetuning 베이스라인 성능을 거의 재현

LoRA 보통 8비트
✔️ How to use QLoRA?
• Huggingface에서 제공하는 transforemers 라이브러리로 로드가능
• peft 라이브러리와 연계를 통해 QLoRA 적용 가능
Making LLMs even more accessible with bitsandbytes, 4-bit quantization and QLoRA
from transformers import BitsAndBytesConfig
double_quant_config = BitsAndBytesConfig(
load_in_4bit=True,
bnb_4bit_use_double_quant=True,
)
model_double_quant = AutoModelForCausalLM.from_pretrained(model_id, quantization_config=double_quant_config)
✔️ IA3 (Infused Adapter by Inhibiting and Amplifying Inner Activations)
• Self-Attention, Cross-Attention에서의 Key, Value 값을 rescale해주는 벡터와 position-wise feed-forward network의 값에 rescale을 해주는 벡터를 추가해서 모델을 튜닝하는 기법
<=> LoRA의 경우에는 hidden state에 새로운 값을 더해주는 기법
•기존에 공개된 LoRA보다 적은 파라미터를 사용하면서 높은 성능
• LoRA 보다 파라미터 업데이트 수도 적으며,
• GPT-3를 in-context learning 했을 때 보다도 성능이 좋음
✔️ LLaMA Adapter
• LLaMA 모델을 instruction 모델로 효율적으로 미세 조정하기 위한 방법
•학습 가능한 프롬프트 토큰을 상위 Transformer 레이어의 입력 텍스트 토큰 앞에 추가해 학습
• 1.2M의 적은 피라미터 수로 각 어댑터를 유연하게 삽입하여 다양한 지식을 부여
• Multi-modal conditioning
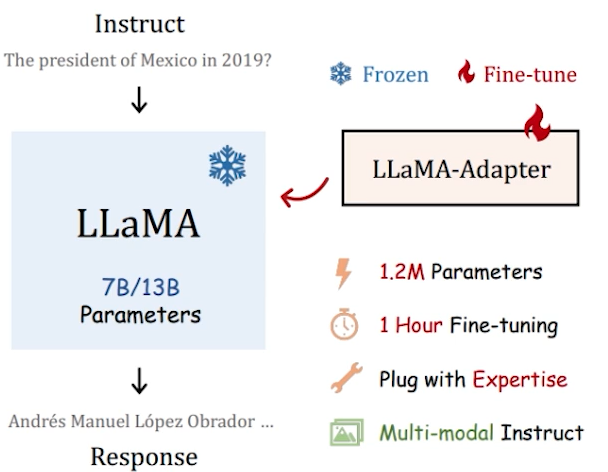
✔️ LLaMA Adapter
• Visual encoder(e.g. CLIP)를 통해 각 scale의 feature를 추출하고 학습 가능 projection 적용
'04_NLP(Natural Language Processing)자연어처리 > LLM' 카테고리의 다른 글
| LLM Evaluation (0) | 2025.02.07 |
|---|---|
| LLM 기반 Data-Centric NLP 연구 (2) | 2025.02.06 |
| Large Language Model 이란? (1) | 2025.02.06 |
| 사전학습 기반 언어모델의 한계점 및 방향성 (1) | 2025.02.06 |
| 문맥기반 언어지식 표현체계 이론 Ⅱ (0) | 2025.02.05 |