✅ LLM 학습 데이터 종류
☑️ LLM 학습 데이터 종류
✔️ LLM 학습 데이터 개요
The History of Open-Source LLMs: Better Base Models (Part Two)

✔️ 사전 학습 데이터
●웹 데이터(Wikipedia, News, Reviews, …) 등을 활용하여 구축
●데이터의 품질 및 다양성이 모델의 성능에 큰 영향을 줌 ⇒ 데이터 전처리 작업이 중요
●품질 및 성능 보장을 위해 필터링/중복 제거 등의 전처리 작업 필요
●영어의 경우 특히 Common Crawl, WebText2, BookCorpus, Wikipedia 등을 소스로 활용
✔️ 사전 학습 데이터의 품질 및 다양성
● LLM 사전 학습 데이터의 “Age”, “Quality”, and “Composition (Domain)”이 평가 성능에 큰 영향을 줌
●특히 다양한 Data sources에 대한 coverage가 가장 큰 영향을 줌 (우측 하단)

✔️ 사전 학습 데이터 구성의 예
● GPT-3의 경우:
○ GPT-3: Common Crawl (filtered), WebText2, Books1, Books2, Wikipedia (total 300 billion tokens)
● LLama의 경우:
○ LLAMA 1: Common Crawl, C4, Github, Wikipedia, Books, ArXiv, StackExchange (total 1.4T tokens)
✔️ 태스크 특화 사전 학습
특정 작업에 특화된 언어 모델을 구축하는 방법 중 하나로, 사전 학습 단계에서 특정 도메인의 데이터를 높은 비율로 구성하여 모델을 학습하는 방법
● LaMDA: Language Models for Dialog Applications:
대화 어플리케이션 구축을 위하여 전체 사전학습 데이터 중 약 절반 (50%)을 대화 데이터로 할당하여 모델 학습
● BLOOM, PaLM:
다국어 특화 LLM 구축을 위해 다양한 언어권의 텍스트를 사전 학습에 함께 활용
● Galactica:
과학 도메인 특화 LLM 구축을 위해 사전학습 데이터의 약 86%를 과학 데이터로 사용
● AlphaCode:
코드 생성 특화 LLM 구축을 위해 사전학습 데이터를 전부 코드 데이터로 사용
☑️ 미세 조정을 위한 학습 데이터
✔️ 미세 조정 데이터
●사전 학습된 모델을 특정 작업에 특화된 데이터셋으로 튜닝하여 활용할 때 사용되는 데이터
●사전 학습 데이터와의 차이점은 입력에 대응하는 정답(출력 또는 선호하는 결과)이 존재
●최근에 LLMs 튜닝을 위하여 아래와 같은 두 종류의 미세 조정 방법론을 활용:
○지시어 (Instruction)와 대응하는 출력 (answer)으로 구성된 데이터로 모델을 학습하여 언어 모델의 자연어 지시에 대한 일반화 성능을 높이는 Instruction tuning
○사람의 선호도 (Human preferences)가 반영된 데이터로 모델을 학습하는 Alignment tuning
● LLM 이전에 활용되던 비-자연어 형식의 데이터는 Instruction과 같은 자연어 형태로 변환하여 LLMs 미세 조정에 활용
✔️ 사전 학습과 미세 조정: InstructGPT
● 사전 학습된 모델을 활용하여 Instruction Tuning 및 Preference Tuning을 수행한 InstructGPT의 예

✔️ Instruction Dataset
● Instruction Tuning:
언어 모델이 자연어 형태의 지시사항(Instruction)을 이해할 수 있도록 하는 미세조정 방법론
● Instruction Dataset:
지시어(Instruction)과 대응하는 출력(Answer)으로 구성된 Instruction 형식의 데이터
○지시어 (Instruction): 해결하고자 하는 작업을 LLM이 이해할 수 있도록 하는 자연어 설명
○출력 (Answer): 지시사항에 대응하는 정답 생성 결과
●기존의 지도학습 패러다임과 유사하나, Instruction Tuning은 비교적 적은 수의 예제만으로 높은 성능 및 새로운 태스크에 대한 일반화가 가능하여, 더욱 효율적인 학습 패러다임으로 주목받고 있음
●데이터셋의 형식 및 품질이 중요함
●다양한 분야에 대한 지시어로 학습한 모델을 Unseen task에 대한 일반화를 목표로 함

● Cross-Task Generalization via Natural Language Crowdsourcing Instructions:
○ 61 distinct NLP tasks에 대한 데이터셋 활용하여 Instruction 형식의 데이터로 mapping 작업 수행. + Human created instructions을 덧붙임
○최종 193k task instances (input-output pairs)
○ Seen tasks에 모델을 학습하고, Unseen tasks에 모델 평가를 수행
→ Instruction에 학습된 모델이 19% 향상된 일반화 성능

● Finetuned Language Models Are Zero-shot Learners (Wei et al., 2022):

○ 62 NLP datasets ⇒ instruction format으로 변환
○ Language Understanding and language generation tasks를 모두 커버
○각 Task마다 10개의 Manual templates를 활용 → Diversity 개선
● Super-NaturalInstructions (Wang et al., 2022):

○ Natural Instructions, FLAN보다 더 diverse, large
○이 데이터로 학습한 모델이 1/16 수준의 파라미터만으로 InstructGPT보다 약 9% 성능 개선
● Stanford Alpaca: An Instruction-following LLaMA Model (합성데이터)

Self-Instruct 방법론 기반 GPT-3.5를 활용하여 Instruction Dataset 생성하여 Alpaca 모델 학습에 활용
● LIMA: Less Is More for Alignment

○단 1,000개의 고품질 instruction dataset으로 학습한 LLaMa 모델이 더 많은 데이터로 학습한 다른 모델보다 Human Evaluation에서 더 높은 수준의 성능을 보였음
→ Instruction Quality..!
✔️ Alignment Tuning
●언어 모델을 특정 작업이나 대상 (인간 등)의 preferences에 따라 튜닝하는 것
●일반적으로 Instruction Tuning이 Alignment Tuning에 포함되나, 여기선 Preference learning의 관점으로 언급

● Training language models to follow instructions with human feedback
Fine-tuned GPT-3를 활용, 다양한 결과를 생성해 놓고 Human preference annotation에 기반한 데이터셋 구축
preference 데이터 기반 Reinforcement Learning with Human Feedback (RLHF) 학습

● Constitutional AI: Harmlessness from AI Feedback
RLHF가 효과적이나, 고품질 human preference annotations를 수집하는 비용/시간이 큼
Human labels 없이 Harmful output 식별을 위한 AI assistant를 학습/활용하는 방법을 실험 및 제안

● RLAIF: Scaling Reinforcement Learning from Human Feedback with AI Feedback
Aligned AI preference를 생성하는 기술에 대한 광범위한 연구 수행 RLAIF가 인간 수준의 성능을 달성

● Direct Preference Optimization: Your Language Model is Secretly a Reward Model
Preference data 구축도 문제지만, RLHF는 학습 프로세스 자체가 불안정함 → Human preferences를 학습하면서 기존의 분포에서 너무 크게 벗어나지 않도록 유지하는 등의 복잡한 학습 과정 요구!!!
Preference data로부터 “directly” LM을 학습하는 방법론 제안

☑️ LLM 데이터 전처리
✔️ 자연어 처리에서의 데이터 품질의 중요성
●데이터 양 vs. 품질: 양도 중요하지만, 품질 및 다양성이 중요!!!

✔️ LLM 데이터 관리 연구들
✔️ 기존 LLM의 데이터 전처리: GPT-3
● Data filtering: CommonCrawl 데이터(웹상)에 대하여 Similarity 기반 filtering 작업 수행
○ High quality document를 분류하는 classifier를 학습하여 활용
● Deduplication: Fuzzy deduplication을 document level로 수행
○문서의 특징에 기반한 Hashing 방법론 활용 (Spark’s MinHashLSH 구현체 활용)
○전체 데이터 집합의 크기를 10% 줄이고, 과적합을 방지(모델의 스케일이 커질 수록 더 중요하다고 언급)
● Diversify: WebText, Books1, Books2, Wikipedia 등의 이미 알려진 high-quality corpora를 추가로 활용
✔️ 기존 LLM의 데이터 전처리: LLaMa
● Data filtering:
○ FastText 선형 분류기를 활용한 언어 식별: 비영어 페이지 제거
○ N-gram 언어 모델을 활용한 low-quality filtering
○ Wikipedia에 대하여 참조된 페이지 분류 모델을 구축: 참조로 분류되지 않은 페이지 제거
○구두점의 존재 유무, 웹 페이지의 단어 및 문장 수와 같은 휴리스틱 기반 품질 필터링 수행
○ Github and Wikipedia: 정규 표현식 등을 활용하여 하이퍼링크/주석/헤더 등 기타 형식화된 부분 제거
● Deduplication: Line-level 중복 제거 수행, Books의 경우 내용이 90% 이상 겹치는 책 제거
● Diversify: CommonCrawl, C4, GitHub, Wikipedia, Books3, ArXiv 등 다양한 소스를 혼합
✔️ The Pile: An 800GB Dataset of Diverse Text for Language Modeling
기존에 공개된 LLM의 사전학습 데이터는 공개되지 않음
⇒ LLM 사전학습을 위한 “The Pile” 데이터셋 및 데이터 구축 프로세스 공개
● 22개의 High-quality corpora로 구성되며, 새로운 전처리 과정 적용
● Dataset의 Diversity의 중요성에 대한 입증:
The Pile에 훈련된 모델이 비슷한 기반의 다른 데이터셋(CC-100)에 비해서 여러 하위 데이터셋에서 두드러진 성능 향상을 보임
✔️ The RefinedWeb Dataset for Falcon LLM
High-quality corpora (e.g., 소셜 미디어, 책, 기술 논문 등)의 활용 없이 Web Data만 활용해서 적절히 필터링/중복 제거만 수행해도 강력한 모델 구축이 가능함을 보임
● CommonCrawl에서 600B tokens의 데이터를 필터링하여 공개
● “Scale first”, “Strict deduplication”, “Neutral filtering”의 3가지 설계 원칙에 기반한 MDR (MacroData Refinement) 방법론 제안
● Zero-shot generalization tasks에서 더 낮은 비용으로 강력한 모델보다 높은 성능 달성

● MDR 설계 원칙에 의거, 다음과 같은 MDR pipeline에 기반하여 데이터 구축
✔️ When Less is More: Investigating Data Pruning for Pretraining LLMs at Scale

● Data quality control이 중요함을 강조

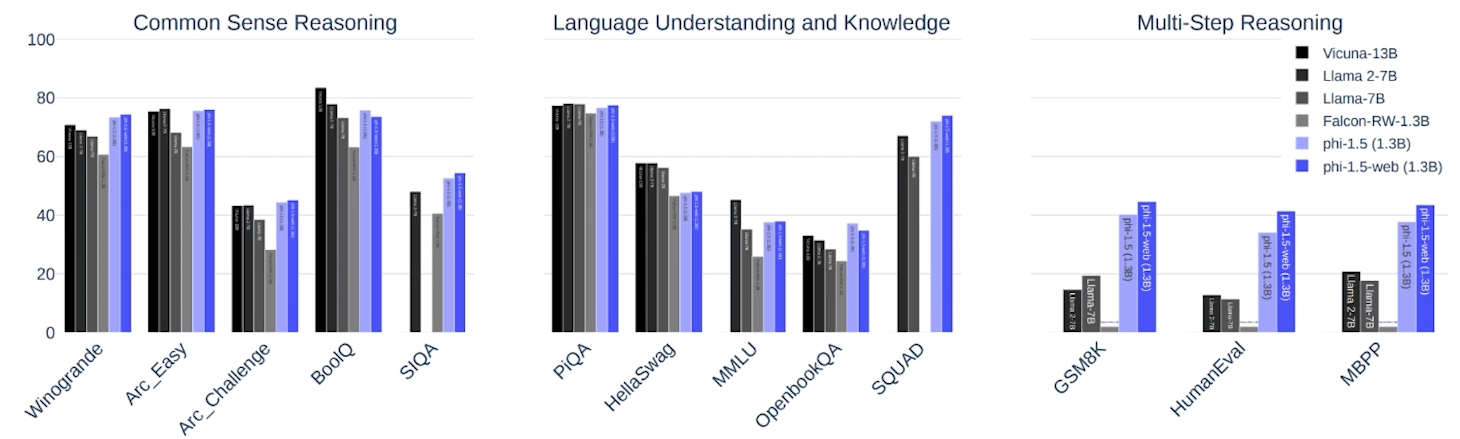
✔️ Textbooks are all you need ii: phi-1.5 technical report
● Quality-based filtering을 수행한 phi-1.5-web이 다음의 3가지 tasks에서 가장 높은 성능을 보임
✔️ D4: Improving LLM Pretraining via Document De-Duplication and Diversification
●데이터 중복 제거 및 다양화를 위하여 Pre-trained LM의 임베딩 활용 ⇒ 훈련 과정의 효율성/효과성 모두 Up!

신중한 단어 선택 ! 성능을 20%높임 !
✔️ Self-Refine: Iterative Refinement with Self-Feedback
● Human problem-solving의 특징? Self-Refinement !
● LLM을 활용하여 생성, 피드백, 정제 등의 Self-feedback 과정을 반복 ⇒ 데이터 품질 자체 개선

☑️ LLM 기반 라벨링 연구
✔️ LLM 기반 데이터 라벨링
새로운 데이터를 구축하거나 기존의 데이터를 증강하는 데 LLM을 활용하는 연구 분야
● LLM 기반 데이터 합성: 라벨링 정보가 존재하지 않는 데이터를 입력으로 LLM을 활용하여 라벨링
● LLM 기반 데이터 증강: 라벨링 정보가 존재하는 데이터를 입력으로 LLM을 활용하여 데이터의 양/품질을 개선
✔️ 증강 연구 (1): LLM-powered Data Augmentation for Enhanced Crosslingual Performance
● Cross-lingual Dataset → 구축 비용이 많이 듦 → LLMs로 데이터셋 증강 → Smaller Models (mBERT, XLMR) 학습
●자동 평가 및 Human Evaluation에서 크게 개선된 결과를 보임

✔️ 증강 연구 (2): Mixture of Soft Prompts for Controllable Data Generation
● LLMs는 주로 Raw text에 학습되므로, Structured dataset에 대한 생성이 제한되는 경향이 있음
●이를 완화하여 LLMs를 활용하여 Structured prediction tasks에 대한 데이터 생성 방법론 제안


✔️ 합성 연구 (1): Vicuna: An Open-Source Chatbot Impressing GPT-4 with 90%* ChatGPT Quality
● 70K user-shared ChatGPT Conversations를 활용, LLaMA를 fine-tuning → Alpaca 대비 큰 성능 개선!

✔️ 합성 연구 (2): DISCO: Distilling Counterfactuals with Large Language Models
● LLM을 활용하여 대규모 Counterfactual data를 생성하는 방법론 제안 (NLI)

✔️ 합성 연구 (3): Large Language Model as Attributed Training Data Generator
●데이터 합성에 활용되는 LLM의 Prompt Engineering에 초점을 맞춰, 길이와 스타일 지정 등의 속성이 부여된 Prompt (AttrPrompt)를 제안/활용하여 기사 분류 데이터셋 합성 ⇒ 데이터 합성시 편향, 다양성, 효율성 등에 대한 다양한 관찰 결과
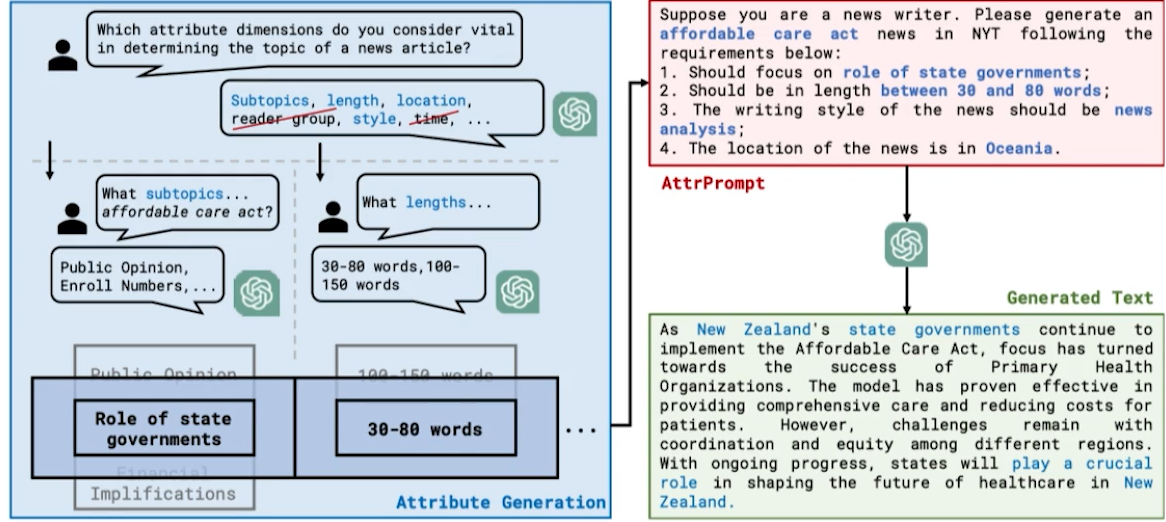
심플 프롬포트를 사용한 합성데이터셋 중요한 편향을 보임 !
✔️ 합성 연구 (4): Instruction tuning with gpt-4
● GPT-4 활용하여 instruction dataset 생성, LLM fine-tuning에 활용 ⇒ zero-shot 성능 크게 개선
● Alpaca dataset을 합성을 위한 seed dataset으로 활용

✔️ 합성 연구 (5): Increasing Diversity While Maintaining Accuracy: Text Data Generation with Large Language Models and Human Interventions
● humans과 LLMs의 협력으로 생성하는 데이터의 다양성과 품질 개선: human-in-the-loop text data generation
● LLMs를 활용한 생성 결과에 적용한 human validation (Label replacement)[36] 과정이 모델 성능을 크게 개선

'04_NLP(Natural Language Processing)자연어처리 > LLM' 카테고리의 다른 글
| LLM 기반 Application (0) | 2025.02.07 |
|---|---|
| LLM Evaluation (0) | 2025.02.07 |
| Large Language Model의 근간 이론들 (1) | 2025.02.06 |
| Large Language Model 이란? (1) | 2025.02.06 |
| 사전학습 기반 언어모델의 한계점 및 방향성 (1) | 2025.02.06 |