✅ LLM Evaluation
☑️ Evaluation
✔️ Overview

기존의 accuracy , f1 score 등 메트릭으로 평가 할수 x / 인간의 특성을 평가해야함 !
✔️ A Systematic Study and Comprehensive Evaluation of ChatGPT on Benchmark Datasets
● QA, 요약, Code generation, 상식 추론, 수학적 문제 해결, 기계 번역, 등 같은 작업을 다루는 다양한 NLP 데이터셋에 대한 ChatGPT의 성능 평가 및 분석 → 140 tasks에 대하여 총 255K 생성 결과 분석

●대부분의 언어 이해 작업에서 우수한 zero-shot 능력을 보임, 수학적 추론 태스크와 같은 일부 작업에서는 정답이 맞았는데 추론 과정이 오답을 보이는 등의 현상이 관측됨
llm 의 진실성 , 최신성, 수학적능력 개선할 필요가 있음
✔️ G-EVAL: NLG Evaluation using GPT-4 with Better Human Alignment
● BLEU, ROUGE → low correlation with human judgments ⇒ GPT-4 as Evaluator !?
✔️ Is ChatGPT a General-Purpose Natural Language Processing Task Solver?
● ChatGPT의 zero-shot reasoning 능력에 대한 실증적 분석
●추론 기능을 요하는 다양한 작업에서 훌륭하나, 시퀀스 태그 지정를 지정하는 NER등 특정 task에서 어려움을 겪음

☑️ Interpretability
✔️ Interpretability
● LLM의 엄청난 생성 능력.. 그러나 Interpretability?

✔️ FLASK: Fine-grained Language Model Evaluation based on Alignment Skill Sets
● LLMs를 평가할 때 작업의 특성을 고려하여 세분화하여 평가해야 함 ⇒ 인간 평가와 더 높은 상관 관계

✔️ Adaptive Chameleon or Stubborn Sloth: Revealing the Behavior of Large Language Models in Knowledge Conflicts
●모델이 기존 가지고 있 지식과 검색된 지식의 충돌(knowledge confict)에 대한 분석 수행! → Counter-Memory 구축
외부에서 가져온 지식과 LLM이 가지고 이던 지식이 출동하는것

● LLM이 parametric knowledge에 의존하는 경향이 있으나, counter-memory가 높은 일관성을 보이는 경우 잘 수용하는 결과를 보였음 → counter-memory가 잘못된 정보이므로, LLM이 이러한 오류에 속아 잘못된 정보 제공을 할 수 있는 문제 존재

● Evidence 의 순서조차도 성능에 영향?
gpt4를 제외한 다른 모델들은 첫벗째질문을 선호하는 경향이 있다
✔️ Benchmarking Foundation Models with Language-Model-as-an-Examiner
● LLMs를 Examiner로 활용하여 평가하는 경우도..
✔️ Judging LLM-as-a-Judge with MT-Bench and Chatbot Arena
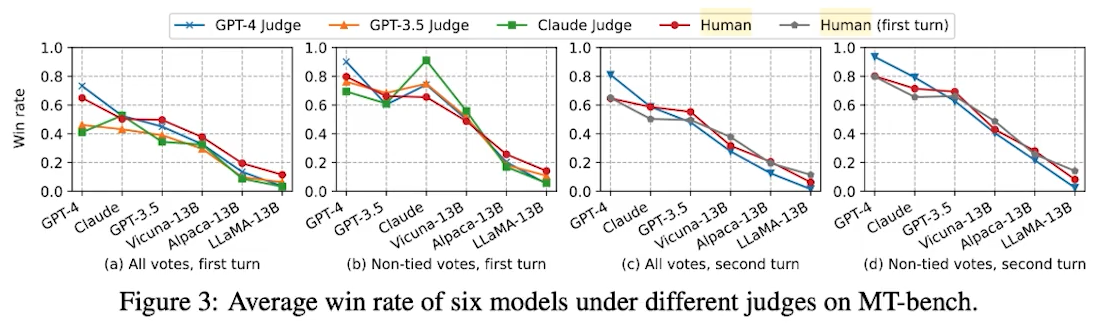
● LLM as Examiner? 인간 선호도와 80% 이상 일치하는 결과 (GPT-4)
인간이 평가 (온라인 평가)
✔️ ALCUNA: Large Language Models Meet New Knowledge
●빠르게 진화하는 세계에서 중요하고 어려운 측면인 새로운 지식을 처리하는 LLM의 능력을 평가!!
인간이 평가 (온라인 평가)

llm 실제 지식이 대처하는 성능이 만족스럽지 않다!
새로운시나리오나 지식을 이용할때 주의가 필요하다!
✔️ Do Large Language Models Know about Facts?
● LLM’s factual knowledge의 정도와 범위를 종합적으로 평가

Hallucination관련된 연구 / 허위상관과계를 밝힘
● Knowledge-intensive tasks에 대하여 심층 분석 수행

a. hop이 증가 할수록 LLM의 성능이 감소하는 현상
b. llm이 구조적데이퍼를포함할때 성능이 감소
c. 다양한 사실적 지문에 분석으로 인해 어려움이 있다
a. 업데이트된 데이터 처리에서 우수하다
b. 어드버설 어택에서는 아직 부족
c. 레이블 정보가 간결하수록 성능이 크게 저하
✔️ HaluEval: A Large-Scale Hallucination Evaluation Benchmark for Large Language Models
● LLMs의 Hallucination을 평가하기 위한 benchmark dataset 제안
●기존 LLMs는 hallucinated contents에 대한 구분 능력이 부족하며, 완화를 위해 retrieval augmentation이 효과적
☑️ Ethics/Trustworthiness
✔️ Toxicity in chatgpt: Analyzing persona-assigned language models
● CahtGPT의 Toxicity 평가/분석: 특정 persona가 할당된 경우, Toxicity 최대 6배 증가

✔️ Should ChatGPT be Biased? Challenges and Risks of Bias in Large Language Models
● LLMs의 편향성에 대한 분석 수행. 개발자로서의 책임감 강조

chat gpt 와 같은 llm에서 편향성의 근원을 탐구하고 이렇한 편향이 가진 윤리적인 함의를 겁토하고 또 다양한 어플리케이션에서 모델을 배포할때 복잡성을 분석
✔️ The Self-Perception and Political Biases of ChatGPT
● ChatGPT의 MBTI 및 정치 편향성 조사

chat gpt의 정치적 성향을 다룬 논문
✔️ Towards Understanding Sycophancy in Language Models
● Can LLMs understand “Sycophancy”? How much does “Sycophancy” affect the behaviors of LLMs?

아첨을 선호함
✔️ Large Language Models are not Fair Evaluators
● Positional Bias? candidate responses의 순서만 바꿔도 성능이 변화함!

● Calibration framework 제안: Multiple Evidence Calibration (MEC) and Balanced Position Calibration (BPC)
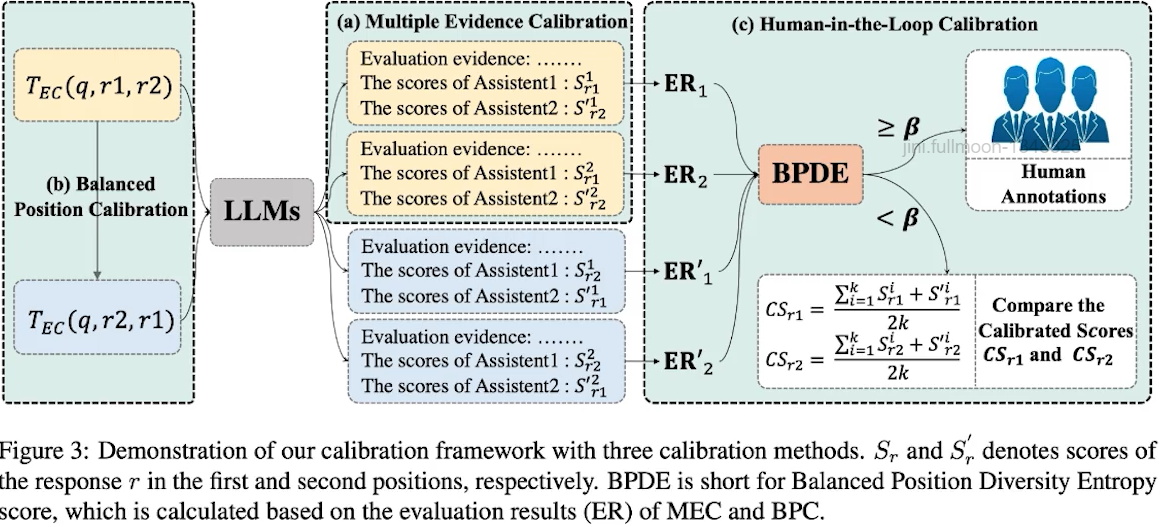
● ChatGPT is not a fair evaluator! ⇔ GPT-4 is a fair evaluator!
✅ LLM Leaderboard
☑️ LLM Leaderboard
✔️ Open LLM Leaderboard
● Open LLM Leaderboard는 세계 최대 머신러닝 플랫폼 Hugging Face에서 운영하고 있으며, 전세계 테크기업과 연구기관이 개발하여 업데이트한 AI 모델을 평가하고 순위를 매겨 Open LLM의 성능을 비교할 수 있음
Open LLM Leaderboard - a Hugging Face Space by open-llm-leaderboard
✔️ MTEB Leaderboard
● MTEB: Massive Text Embedding Benchmark ( 임베딩관련)
GitHub - embeddings-benchmark/mteb: MTEB: Massive Text Embedding Benchmark
✔️ Chatbot Arena: Benchmarking LLMs in the Wild with Elo Ratings
● Crowdsourced open platform for LLM evaluations으로, 20만개의 human preferences 기반으로 구축됨
Chatbot Arena: Benchmarking LLMs in the Wild with Elo Ratings | LMSYS Org
✔️ Big Code Models Leaderboard
● HumanEval benchmark와 MultiPL-E 에서 multilingual code generation 모델의 성능 비교를 위함
Big Code Models Leaderboard - a Hugging Face Space by bigcode
✔️ Open ASR Leaderboard
●음성 인식 모델의 순위 및 평가를 위함
● Word Error Rate (WER), Real-Time Factor (RTF) 등 활용
Open ASR Leaderboard - a Hugging Face Space by hf-audio
✔️ LLM Perf Leaderboard
●다양한 하드웨어, 백엔드 및 최적화 환경에서의 LLMs의 처리 성능(latency, throughput, memory & energy) 평가 목표
Open ASR Leaderboard - a Hugging Face Space by hf-audio
✔️ Open Multilingual LLM Evaluation Leaderboard
●다국어 LLMs 평가를 위함. 29개 언어 지원, 지속적으로 다른 언어 지원 확장 진행 중
Open Multilingual Llm Leaderboard - a Hugging Face Space by uonlp
✔️ AlpacaEval Leaderboard
● AlpacaEval evaluation set에 대한 리더보드, GPT-4와 같은 LLM을 참조 모델로 활용하여 답변 선호도를 평가!
✔️ HELM Leaderboard
● HELM? A Holistic framework for EvaLuating foundation Models
●다양한 모델을 다양한 시나리오 그룹에 대하여 다양한 관점으로 평가하기 위함
HELM Lite - Holistic Evaluation of Language Models (HELM)
✔️ Hallucinations Leaderboard
● TruthfulQA, HaluEvals, XSum, CNN/DM, Self-CheckGPT 등을 활용하여 LLMs의 Hallucinations를 평가하기 위함
OpenCompass LLM Leaderboard - a Hugging Face Space by opencompass
✔️ OpenCompass 2023 LLM Annual Leaderboard
● LLMs에 대한 Annual Leaderboard로, 매년 다양한 LLMs에 대한 평가를 목표
language, knowledge, reasoning, creation, long-context, agent 등 다양한 역량을 평가
● LLMs에 대한 Annual Leaderboard로, 매년 다양한 LLMs에 대한 평가를 목표 language, knowledge, reasoning, creation, long-context, agent 등 다양한 역량을 평가
✔️ ZeroSCROLLS: Zero-Shot CompaRison Over Long Language Sequences
● Long texts 생성 평가 목적으로, benchmark에는 요약, QA, 감정 분류 및 information reordering 등 10개의 tasks 평가
OpenCompass LLM Leaderboard - a Hugging Face Space by opencompass
✔️ Open Ko-LLM Leaderboard
● Upstage와 AI-Hub를 통해 데이터셋을 제공하는 NIA가 공동 주최한 한국어 LLM의 성능을 객관적으로 평가하기 위한 리더보드
'04_NLP(Natural Language Processing)자연어처리 > LLM' 카테고리의 다른 글
| LLM 기반 Prompt Engineering (1) | 2025.02.07 |
|---|---|
| LLM 기반 Application (0) | 2025.02.07 |
| LLM 기반 Data-Centric NLP 연구 (2) | 2025.02.06 |
| Large Language Model의 근간 이론들 (1) | 2025.02.06 |
| Large Language Model 이란? (1) | 2025.02.06 |