✅ 초기의 사전학습 언어 모델
☑️ 사전학습과 미세조정
✔️ 사전학습 (Pretrain)과 미세조정 (Fine-tuning)
사전학습의 목표
• unlabeled text corpora로 부터 유용한 language representation을 배우는 것
•사전학습 모델은 사전에 언어를 잘 이해했기 때문에, downstream task에 대해 라벨링된 데이터를 추가로 학습하여 좋은 성능을 얻을 수 있음
• E.g. 수능 국어(특정 downstream task)를 공부할 때, 글을 모르는 사람은(단순히 데이터로만 학습) 수능 국어에 능숙해 지는 데에 오랜 시간이 걸리고 (학습을 비교적 잘 하지못함), 사전에 글을 배운 사람 (사전학습 모델)은 비교적 수능 국어를 더 잘 익힘 (학습을 비교적 잘함)
집현전 중급 2조: BERT - Google Slides

✔️ 사전학습의 동기
• 라벨링된 데이터는 수가 부족할 뿐만 아니라, 구축에 많은 시간과 비용이 소모
• 라벨링되지 않은 데이터는 인터넷에서 쉽게 얻을 수 있음 (위키피디아 문서, 뉴스기사 등)
• 따라서, 라벨링되지 않은 데이터에 라벨을 추가하여 라벨링 데이터로 만들면, 인터넷의 방대한 데이터로 언어를 학습할 수 있음
⇒ 준지도학습 (Semi-supervised Learning) / 비지도학습 (Unsupervised Learning)


✔️ ELMo(Embeddings from Language Models)
• ELMo는 Pre-trained word representation을 얻기 위해 만들어진 사전학습 모델
•기존의 문법적, 문맥적 정보를 통한 단어벡터를 얻는 것은 매우 어려운 작업
•기존의 사전학습된 단어 임베딩은 ‘사과’ 단어를 동일한 벡터로 변환
• ELMo는 이를 사전학습된 Bi-LSTM을 사용하여, 매번 다른 단어 임베딩을 획득
[자연어처리][paper review] ELMo : Deep contextualized word representations


✔️ ELMo의 학습 과정


☑️ GPT-1
✔️ GPT (Generative Pre-trained Transformer)
• Unlabeled text corpora에 대해 Casual Language Modeling (CLM)을 진행
• Transformer의 Decoder 구조만 사용 (Decoder-only) ( Auto- Regressive)
• Down-stream에 대한 Fine-Tuning으로 성능향상
•이전의 접근방식들과는 다르게, 모델 구조의 작은 수정만으로 효과적인 Transfer Learning을 수행


✔️ GPT의 사전학습
• Causal Language Modeling (CLM)
•문장의 이전 단어들을 기반으로 다음 단어를 예측하는 모델링 기법으로, Masked Self-Attention을 통해 구현

✔️ GPT의 미세조정 (Fine-tuning)
•사전학습 후에 Task 별로 모델 구조를 수정하여 지도학습 진행
• GPT-1은 당시 12개의 Down-stream task중 총 9개에서 SOTA를 달성

모델과 task 와의 1:1 관계 / fine tuning 한계가 있었음
☑️ BERT
✔️ BERT (Bidirectional Encoder Representations from Transformer)
• Unlabeled text corpora에 대해 Masked Language Modeling (MLM) 및 Next Sentence Prediction (NSP) 진행
• Transformer의 Encoder 구조만 사용 (Encoder-only)
• Down-stream에 대한 Fine-Tuning으로 성능향상
• BERT 이후 다양한 사전학습 방법 및 사전학습 모델 구조 개선 등의 연구가 진행됨


✔️ BERT의 사전학습
Task 1: Masked Language Modeling (MLM)
문장 내 일부 토큰들을 [MASK]로 교체 후, 앞뒤 문맥을 기반으로 [MASK]를 예측하는 모델링 기법
• BERT는 전체 토큰 중 15%를 [MASK]로 변경

✔️ BERT의 임베딩
BERT의 입력은 3가지 임베딩의 합으로 계산
• Token embeddings: 각 토큰에 대한 WordPiece 임베딩 벡터를 제공
• Segment embeddings: sentence pair를 구분지을 수 있는 정보를 제공
• Position Embeddings: Multi-head Attention은 양방향으로 작용하기 때문에 방향성이 없음. 따라서, 방향성에 대한 정보를 제공하기 위해 Positional Embedding을 추가로 더해줌
집현전 중급 2조: BERT - Google Slides

✔️ BERT의 Special Tokens
• [CLS] (Classification Token): 입력 첫번째 token은 항상 [CLS] 토큰으로, 전체 token sequence의 맥락이 반영된 벡터를 출력함
• [SEP] (Separator Token): Segment Embedding과 함께, 문장 쌍을 구분지을 수 있도록 [SEP] token 을 Sentence Pair 속 두 문장의 사이에 넣어줌
집현전 중급 2조: BERT - Google Slides

✅ 고급 언어 모델링 기법
☑️ Encoder 기반 언어 모델
✔️ Encoder-only models (auto-encoding models)
Encoder-only models (auto-encoding models)
•문장 분류 (Sentence Classification), 개체명 인식(named entity recognition), 추출형 질의응답(extractive question answering) 등 자연어 이해(NLU; Natural Language Understanding) 과제에 적합
•모델이 입력 시퀀스 전체에 접근할 수 있기 때문에, 어떤 사전 훈련 방법으로 문맥을 학습시키는 지가 핵심 BERT는 Masked Language Model으로 Encoder-only 사전학습 모델의 시작을 열음
• BERT-like (BERT, RoBERTa, ALBERT, DistilBERT, ELECTRA...)
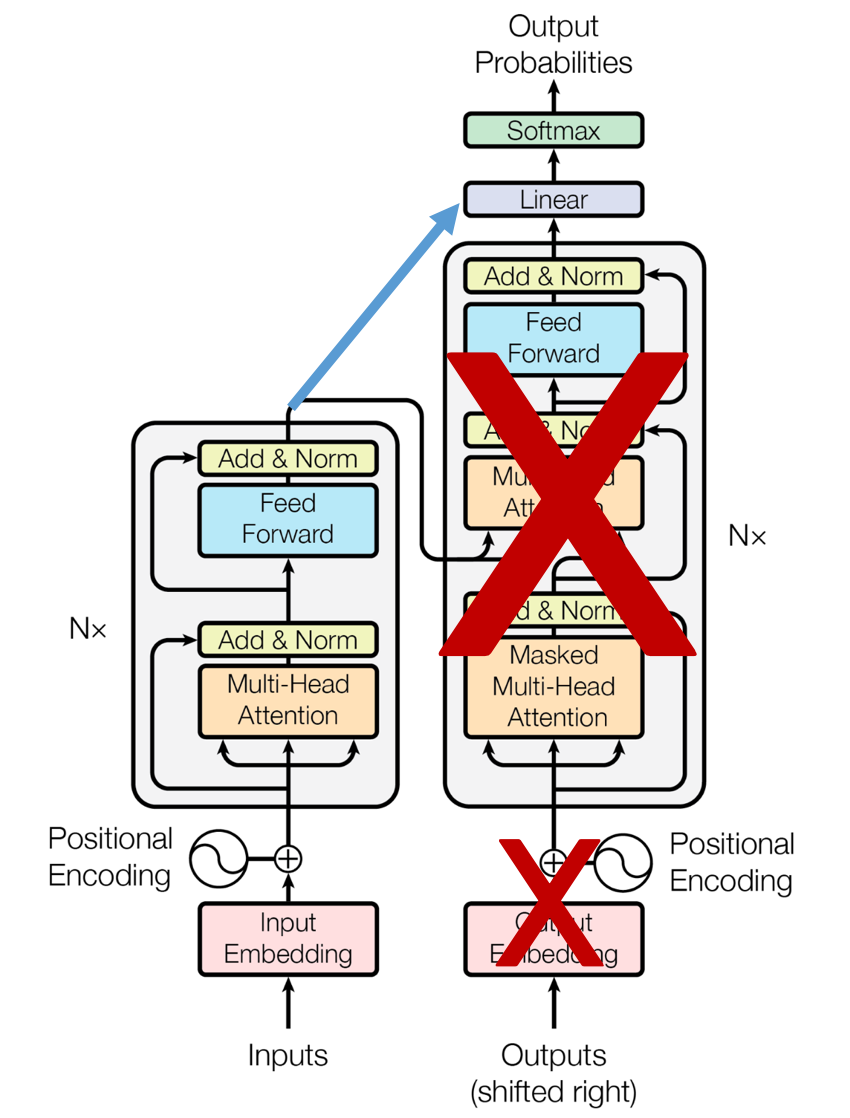
✔️ XLNet (eXtended Language NETwork)
•기존의 BERT는 MLM을 사용해 순차적인 언어 이해를 모델링하는 데 제한이 있었음
→ XLNet은 순열 기반 언어 모델링(Permutation Language Modeling, PLM)을 도입
• PLM은 다양한 단어 순서를 고려하여 양방향 컨텍스트를 효율적으로 학습함
•자동 회귀(Auto-regressive) 특성과 자동 인코딩(Auto-encoding) 장점을 결합하여 텍스트 데이터에서 더 나은 성능을 보임

✔️ XLNet의 Permutation Language Modeling
Permutation Language Modeling
• P3번 토큰을 예측할 때 permutation 시퀀스 고려
•양방향 context 고려 → AR단점 극복
Masking 제거 → AE단점 극복

✔️ RoBERTa
• BERT의 hyper-parameter 및 학습 데이터 사이즈 등을 조절함으로써 가장 최적화된 BERT모델을 제시 → 학습시간, Batch size, Max sequence length, Train data 증가
• Next Sentence Prediction (NSP)제거, Dynamic masking 도입
• BERT의 구조적 변화 없이 모델 성능 개선

✔️ RoBERTa의 Dynamic Masking
Large Language Models: RoBERTa - A Robustly Optimized BERT Approach | Towards Data Science

✔️ ELECTRA (Efficiently Learning an Embedding to Classify Token Replacements Accurately)
•작은 모델인 Generator와 실제 모델인 Discriminator를 사용하여 효율적인 학습
• Generator는 입력 텍스트의 일부 토큰을 마스킹하고 이를 예측하는 역할을 함
• Discriminator는 각 토큰이 실제 텍스트에서 오는 것인지, 아니면 Generator에 의해 생성된 가짜 토큰인지를 판별하는 역할을 함
• ELECTRA의 핵심은 모든 토큰에 대해 진위 여부를 예측하는 Replaced Token Detection (RTD) 방식을 사용하는 것. (BERT는 15%의 [MASK] 토큰에 대해서만 학습)
•모델 크기, 데이터, 컴퓨터 리소스가 동일한 조건에서 기존 BERT 성능을 능가
• RoBERTa나 XLNet 대비 ¼ 의 계산량만으로 비슷한 성능
✔️ 기존 BERT의 단점
•비일치 문제: [MASK] 토큰은 사전학습 중에는 나타나지만 미세조정 중에는 나타나지 않음
•비효율적 사전학습: MLM에서는 loss가 마스크된 토큰만을 사용하여 계산되므로 토큰의 15% 에서만 제공되어 비효율적
The Ever-evolving Pre-training Tasks for Language Models | by Harshit Sharma | Towards AI

✔️ ELECTRA의 Replaced Token Detection (RTD)
• RTD는 각 토큰이 ‘replaced’ 또는 ‘original’로 분류되므로 비효율적 사전학습 및 비일치 문제 해결
• Discriminator를 실제 사전학습 모델로 사용하며, Generator는 사전학습 후에 사용하지 않음
✔️ ALBERT (A Lite BERT)
•모델 크기가 크면 클수록 일반적으로 좋은 성능을 보이나, 크기를 줄이고 성능을 높이는 사전학습 모델 개발
•메모리 문제(OOM; Out Of Memory), 훈련 시간 증가, Model Degradation(큰 모델이 오히려 낮은 성능)
•모델 크기를 줄이고, 성능을 높이기 위해 Cross-layer parameter sharing, Sentence order prediction (SOP), Factorized Embedding parameterization 적용
✔️ ALBERT의 Cross-layer Parameter Sharing
•모델의 모든 레이어에서 동일한 가중치를 재사용함으로써 모델의 크기를 줄이고 학습 파라미터의 수를 감소시키는 기법
A Visual Guide to ALBERT (A Lite BERT)

✔️ ALBERT의 Sentence-Order Prediction (SOP)
• NSP → SOP:
주어진 두 문장이 실제로 이어지는지 → 문장이 원래의 순서대로 주어졌는지


✔️ ALBERT의 Factorized Embedding parameterization
• 모델의 크기를 줄이기 위해 큰 단어 임베딩을 두 개의 작은 행렬로 분해하는 기법
• 기존 파라미터 V*H를 V*E + E*H로 줄임

✔️ SpanBERT
• BERT의 MLM을 확장하여 길이가 다른 연속적인 텍스트 스팬을 가리는 Span Masking 도입
• Span-boundary Objective (SBO)로 더 나은 표현을 학습, 스팬의 양 끝에 위치하는 토큰들이 서로 밀접한 관계를 가지도록 함
• SpanBERT는 질의응답(Question Answering)과 핵심 구 추출(Coreference Resolution) 과 같은 다운스트림 작업에서 뛰어난 성능을 보임

✔️ SpanBERT의 Span Masking & Span-boundary Objective
• Span Masking: 시퀀스의 15%가 마스킹 되도록 만드는데 이때, span의 길이를 geometric distribution에 의해 선택하고, 랜덤하게 span의 시작위치를 선택
• Span-boundary Objective (SBO): 모델이 마스크된 스팬의 경계 토큰을 예측하도록 하는 목표로, 스팬의 첫 번째와 마지막 토큰에 대한 정보 제공
The Ever-evolving Pre-training Tasks for Language Models | by Harshit Sharma | Towards AI

✔️ DistilBERT (Distilled BERT)
•크기와 복잡성은 줄이면서 원래의 BERT 모델과 유사한 성능을 유지하도록 설계된 ‘Distilled’ 버전
•지식증류(Knowledge Distillation) 기술을 활용하여 큰 BERT 모델로부터 지식을 추출하여 작은 모델로 전달
• DistilBERT는 BERT 대비 약 40% 작지만, 원래 BERT 모델의 97% 수준의 성능 달성
•학습 시간과 자원을 효과적으로 절약하면서 자연어 이해 작업(NLU)에서 높은 효율성과 성능을 제공
✔️ DistilBERT의 지식증류
•크기와 복잡성은 줄이면서 원래의 BERT 모델과 유사한 성능을 유지하도록 설계된 ‘Distilled’ 버전
•지식증류(Knowledge Distillation) 기술을 활용하여 큰 BERT 모델로부터 지식을 추출하여 작은 모델로 전달
(NLP) DistilBERT 리뷰 및 설명 | Simon's Research Center

✔️ DistilBERT의 학습
• Teacher - Student Cross Entropy (Distillation Loss)
• Student Masked Language Modeling Loss (MLM Loss)
• Teacher - Student Cosine Embedding Loss

✔️ Student Cross Entropy
• ‘Distillation’이란, 큰 모델인 ‘teacher’에서 작은 모델인 ‘student’로 지식을 전달하는 과정. teacher 모델이 예측한 확률 분포를 student 모델이 모방하도록 함
• Distillation Loss는 teacher 모델의 소프트 타깃(softened probability distribution)과 student 모델이 생성한 출력 간의 Cross Entropy를 계산하여, student가 teacher의 출력을 가능한 한 정확하게 재현하기 위함

✔️ DistilBERT의 MLM Loss
• DistilBERT도 BERT와 유사하게 입력에서 일부 토큰을 무작위로 마스킹하고, 모델이 이 마스킹된 토큰을 예측하도록 함
• Student MLM Loss는 실제 토큰과 student 모델에 의해 예측된 토큰 간의 Cross Entropy Loss를 계산하여, student가 입력 문맥에 따른 단어 예측 능력을 갖추도록 함
•즉, 기존 BERT의 MLM 능력을 모방하기 위함
✔️ DistilBERT의 Student Cosine Embedding Loss
• Student Cosine Embedding Loss는 teacher와 student 모델의 출력 임베딩 벡터 간의 방향을 일치시키기 위해 사용
• Cosine Embedding Loss는 두 벡터 간의 cosine similarity를 최대화하여, student가 teacher와 유사한 방향으로 벡터를 임베딩하도록 유도
•즉, student 모델이 단순히 확률 분포를 모방하는 것을 넘어서 벡터 공간에서 비슷한 의미 구조를 형성하게 하기 위함

✔️ DistilBERT의 성능
• BERT-base를 Teacher 모델로 사용하여, 파라미터 수를 180M → 110M으로 줄임

✔️ DeBERTa (Decoding-enhanced BERT with disentangled attention)
•기존 BERT에서 상대적인 토큰의 위치 계산에 문제점 개선
• DeBERTa는 disentangled attention mechanism과 enhanced mask decoder 사전학습 방법을 도입
• Disentangled attention: 토큰 간의 콘텐츠(content)와 위치(position) 정보를 분리하여 처리
• Enhanced mask decoder (EMD): 각 토큰의 절대적 위치 정보를 사용하여 마스킹된 토큰을 더 정밀하게 예측
✔️ DeBERTa의 Disentangled attention
•기존 어텐션 구조를 Content와 Position으로 분리하여 처리하는 방식
•상대적인 위치 정보를 반영하기 위해, relative position embeddings 사용
• Disentangled Attention Mechanism: Content에 대한 어텐션 가중치와 Position에 대한 어텐션 가중치를 결합하여 최종 어텐션 스코어를 계산하는 어텐션 메커니즘. Content-to-Content (C2C), Content-to-position (C2P), Position-to-content (P2C)의 상호작용을 고려
• Content-to-Content (C2C): 기존의 BERT에서 사용되는 self-attention과 유사함. 모델은 각 토큰의 ‘내용 (content)’ 정보를 기반으로 다른 토큰들과의 관계를 학습함. 즉, 단어의 의미적인 상황(context)을 이해하는 데 중점을 둠
• Content-to-Position (C2P): 토큰의 '내용(content)'에 기반하여 해당 토큰이 문장에서 위치하는 '위치 (position)'와의 관계를 학습함. 즉, 단어의 content와 position 사이의 관계로, 단어 위치에 따른 단어의 의미 정보를 학습
• Position-to-Content (P2C): 토큰의 '위치(position)' 정보로부터 다른 토큰들의 '내용(content)'과의 관계를 학습함. 즉, 문장 내의 특정 위치에서 어떤 종류의 단어나 개념이 등장할 가능성이 높은지 예측 학습
• Position-to-Position (P2P): 토큰의 '위치(position)' 정보 사이의 관계를 고려

✔️ Content-to-Position과 Position-to-Content의 차이
DeBERTa (He et al., 2021, ICLR)

✔️ DeBERTa의 Disentangled attention
기존 BERT의 문제점
• BERT의 단어 임베딩은 Content Vector에 Position Embedding 값을 단순히 더해서 만듦
→ Content-to-content와 Content-to-position만 고려
• Position-to-content를 추가로 학습할 필요가 있음
(Position-to-position은 토큰 간의 상대적 위치로, 고려하지 않음)

DeBERTa (He et al., 2021, ICLR)


✔️ DeBERTa의 Enhanced mask decoder (EMD)
•기존 BERT는 입력을 token embeddings, segment embeddings, position embeddings로 구성하여 absolute position 구성

•기존 BERT와 다르게, 단어의 absolute position을 미리 예측하지 않고, softmax 이전에 absolute position embedding을 더하여 예측
🪢 [DeBERTa] DeBERTa: Decoding-Enhanced BERT with Disentangled-Attention - AI/Business Study Log

단어의 절대적위치보다 단어의 상대적위치에 주목하게 되었다!
✔️ XLM (Cross-lingual Language Model)
•다양한 언어를 모델링 하기 위해 설계된 다국어 언어 모델
• Masked Language Model (MLM)과 Translation Language Model (TLM)을 사용하여 사전학습
• TLM을 통해 다국어 텍스트의 공유된 표현을 학습하여, 본질적으로 언어에 중립적인 특징을 학습함
•언어 중립적인 특징을 학습하여, 소수 언어 (low-resource language) 혹은 번역 작업에서 우수한 성능을 보임
• Translation Language Modeling (TLM): 기존 비지도학습 사전학습 방법과 다르게, 지도학습 데이터인 병렬 데이터셋을 사용하여 소스 문장과 타깃 문장을 한 입력 데이터에 합쳐서 구성. Cross-linguality 증가를 목적으로 함

• MLM과 TLM을 같이 사용하였을 때, 모든 언어에서 좋은 성능을 보임
• Nepali를 단독으로 학습하는 것 보다, English와 Hindi와 같이 사용했을 때 PPL이 가장 낮음
→ TLM이 언어의 중립적 특징을 학습함

☑️ Decoder 기반 언어 모델
✔️ Decoder-only models (auto-regressive models)
Decoder-only models (auto-regressive models)
•유창성이 필요한 챗봇, 음악생성 등 자연어 생성(NLG; Natural Language Generation) 과제에 적합
• Causal Language Modeling으로 학습되기 때문에 Masked Language Modeling 기법으로 미래 시점의 단어들을 가리는 auto-regressive 방법을 채택. 이로 인해, 사전학습 방법 보다, 모델의 크기와 고퀄리티의 데이터 학습이 관건
• GPT-like (GPT, GPT-2, GPT-3, LaMDA, CTRL, Transformer XL...)
✔️ GPT-2
• GPT-2는 OpenAI가 개발한 언어 예측 모델로, 딥러닝 기반의 자연어 생성에 사용
• GPT-1과 동일하나 모델 및 학습 데이터 크기와 약간의 모델 구조 변경
•비지도학습 (랭귀지모델과fewshot leaner)만으로 NLP task를 해결할 수 있는 General Language Model에 대한 첫 연구
-> 정말 핵심적인 논문은 GPT2였다 !
GPT2가 chatGPT를 넘어서는가장 핵심적인 논문!

✔️ GPT-3
• GPT-2의 후속 모델로, 더 큰 모델과 더 많은 확장된 데이터셋을 사용하여 학습된 초기 LLM
• 175B 파라미터 크기로, 당시 공개된 모델 중 압도적인 크기. 아직까지도 굉장히 큰 규모의 LLM
•다양한 작업에 대해 미세 조정 없이 ‘few-shot’ 또는 ‘zero-shot’ 추론으로 높은 성능 달성
• In-context Learning의 시초

✔️ Encoder-decoder models (sequence-to-sequence models)
Encoder-decoder models (sequence-to-sequence models)
•번역, 요약, 생성기반 질의응답(generative question answering) 등 입력과 입력된 문장을 이해하여 생성하는 필요한 자연어 이해 및 생성이 모두 필요한 과제에 적합
•입력 시퀀스를 이해하고, 그에 상응하는 출력 시퀀스를 생성하는 능력을 모두 갖추어야 하므로, 이 두 가지 측면을 모두 고려하는 사전학습 방법을 찾는 것이 관건
• BART/T5 like (BART, mBART, Marian, T5, Meena...)
Transformer Explained | Papers With Code

✔️ BART (Bidirectional and Auto-Regressive Transformer)
• BERT는 Encoder 구조이기 때문에, 텍스트의 전반적인 맥락을 잘 이해해야하는 NLU Tasks에 유리하지만, NLG Taks에 부적합
(자연어이해 유리, 자연어생성 불리)
• GPT는 Decoder 구조이기 때문에, 맥락에 기반해 연속적인 텍스트를 생성하는 NLG Tasks에 유리하지만, 양방향 Context를 참조하지 못하여 NLU Tasks에 부적합
(자연어이해 불리, 자연어생성 유리)
• Encoder-Decoder (Seq2Seq) 구조에 어울리는 Pre-training 기법 실험
• 텍스트에 노이즈를 더하고, 노이즈를 복구하는 Denoising Auto-encoding 기반 사전학습 진행

✔️ BART의 사전학습 & 미세조정

✔️ BART의 사전학습
Denoising 사전학습 방법 분석
• Token Masking : 토큰을 Masking하고, 이를 복구
• Token Deletion : 토큰을 랜덤으로 삭제하고, 이를 복구
• Token Infilling : 연속된 여러 개의 토큰 스팬을 masking하고 이를 복구 (길이 또한 복구)
• Sentence Permutation : 문장을 랜덤하게 섞고나서 이를 다시 복구 (성능향상에 가장 핵심!)
• Document Rotation : 하나의 토큰이 랜덤으로 선택되고, 문서가 섞여 해당 토큰이 문서의 시작지점을 찾는 방식

• Text Infilling과 Sentence Shuffling을 같이 진행 했을 때, 성능이 가장 좋음

(16) Three Transformer Papers to Highlight from ACL2020 | LinkedIn

✔️ BART의 미세조정
•분류 태스크의 경우
Decoder의 마지막 토큰 Hidden states를 사용하여 Classifier 학습

•번역 태스크의 경우
단일 영어 모델이기 때문에, Randomly Initialized Encoder를 사용

✔️ BART의 미세조정 - NLU

인코더 디코더에서 모두 좋은 성능을 보임!
✔️ MASS (Masked Sequence to Sequence Pre-training)
• BERT와 Seq2Seq 학습 사이의 간극을 메우는 접근법인 Masked Sequence to Sequence Pre-training를 적용
•문장의 연속된 일부분을 마스킹하고, 해당 부분을 예측하기 위해 나머지 부분을 사용
•모델이 마스킹된 부분을 복원하는데 집중하여 문맥 이해를 향상시키고, 시퀀스 생성 능력을 강화하기 위함
• BERT의 MLM을 Seq2Seq으로 확장


✔️ T5 (Text-to-Text Transfer Transformer)
•기존 PLM이 Downstream Task에 대해 미세조정하기 때문에, Task별로 서로 다른 레이어를 각각 만들고 학습해야 함. 따라서, NLP Task를 하나의 통일된 구조로 푸는 Text-to-Text Transfer 방법이 적용된 T5 제안
•동일한 모델 구조를 사용하여, 미세조정을 위한 Prefix 및 Task별 형식에 맞는 Text 전처리만을 하는 방식으로 여러 Task 해결


✔️ T5의 Text-to-Text Transfer
•다양한 Downstream task의 input format을 Text Sentence로 변환




✔️ T5의 사전학습
• Encoder-Decoder 구조가 Decoder-only보다 효율적
• Objective: MLM > Denoising > Language Modeling (CLM)


• Masking rate는 15%가 가장 적절
•최종 사전학습
• Objective: MLM (Replace spans)
• Masking rate: 15%
• span length: 3
-> 최적의 값을 찾아냄 !

•모델의 사이즈가 커질 수록 높은 성능 달성
• Encoder-Decoder 구조에서 최초로 모델과 데이터를 대규모로 키우는 Scale Up 연구
• GPT-3와 다르게 Encoder-Decoder 구조가 더 높은 성능을 나타냄을 강조

☑️ Scale Down 및 Scale Up
✔️ 모델 Scale Down & Scale Up
• Language Model Scale Down: 사전학습 모델의 크기를 줄이거나 유지하면서 모델의 성능을 높이는 모든 연구
• Language Model Scale Up: 언어모델과 데이터의 크기를 키워서 모델의 성능을 급격히 높이는 모든 연구
The Promise and Perils of Large Language Models | Two Sigma Ventures


✔️ Scale Down - 딥러닝 모델 크기 증가에 따른 문제점
•메모리 제한 : 점점 커지는 배치 크기로 인해 사전 학습 시 메모리 제한이 중요한 이슈가 되고 있으며, 특히 대형 언어 모델의 학습과 사용 시 메모리 문제가 심각해짐
•학습/추론 속도 : 모델 크기 증가로 인해 학습과 추론 시간이 길어짐
•성능 저하 : 큰 모델은 과적합 위험이 있으며, 이를 방지하기 위해서는 더 많은 양질의 데이터가 필요함
•실용적 문제 : 대형 언어 모델 사용을 위해 고가의 GPU 서버가 필요하며, 모바일이나 간단한 서비스 환경에서는 사용이 제한적임
→ 모델의 크기를 줄이는 Scale Down 연구 촉발
✔️ Scale Down - 대표적인 사전학습 모델
• ALBERT
• DistilBERT
• TinyBERT (다루지 않음)
• MobileBERT (다루지 않음)
• Q-BERT (다루지 않음)
• Q8BERT (다루지 않음)
✔️ Scale Down - 대표적인 기술

✔️ Scale Up - 딥러닝 모델 크기 증가가 주는 이점
•성능 향상: 모델 크기를 키우면 처리 능력과 정확도가 상승하여 더 나은 결과를 얻을 수 있음
•높은 성능: 큰 모델은 더 많은 데이터를 학습할 수 있어 복잡한 패턴과 관계를 더 잘 이해하고 반영
•다양한 Task 수행: 다양한 NLP Task에 걸쳐 뛰어난 범용성을 보임 (ChatGPT, BARD, HyperCLOVA) •작은 데이터로 일반화: 인간과 유사하게 Zero-shot, Few-shot을 수행할 수 있음
•지식 통합: 대규모 모델은 방대한 정보를 내재화하여 풍부한 지식으로 다양한 곳에 사용될 수 있음
→ 모델의 크기를 늘리는 Scale Up 연구 촉발
✔️ Scale Up - Scaling Laws for Neural Language Models
• LM의 성능은 모델의 파라미터 수, 데이터 사이즈, 계산량에 의존
→ 모델 사이즈가 8배 증가할 때 데이터가 약 5배 증가하면 성능 향상 보장

✔️ Scale Up - 대표적인 사전학습 모델

✔️ Scale Up - 대표적인 사전학습 모델
(16) Large Language Models are Taking Over 2023 | LinkedIn

'04_NLP(Natural Language Processing)자연어처리 > LLM' 카테고리의 다른 글
| Large Language Model 이란? (1) | 2025.02.06 |
|---|---|
| 사전학습 기반 언어모델의 한계점 및 방향성 (1) | 2025.02.06 |
| 의미기반 언어 지식 표현 체계 이론 (0) | 2025.02.05 |
| 언어모델 평가 방법 (1) | 2025.02.04 |
| 카운트 기반 언어모델 (0) | 2025.02.04 |