✅ Large Language Model 개요
☑️ LLM의 정의
✔️ What is Large Language Model(LLM)?
•기존 언어모델의 확장판 => 방대한 파라미터 수를 가진 언어모델을 의미

✔️ Large Language Models 시대 = Foundation Models의 시대
✔️ 창발성 (Emergent ability): 단일 모델로 여러 Task를 처리
모델과 task의 관계가 1:1 -> 1:N 넘어가는 reset moment !
✔️ 새로운 인공지능 개발 방식 = 육수 하나만 잘 끓이면 되는 시대
✔️ Large Language Models 춘추전국시대
✔️ LLM의 핵심 - Human Alignment (Human Feedback)
https://product.kyobobook.co.kr/detail/S000008824253
The Alignment Problem | Christian, Brian - 교보문고
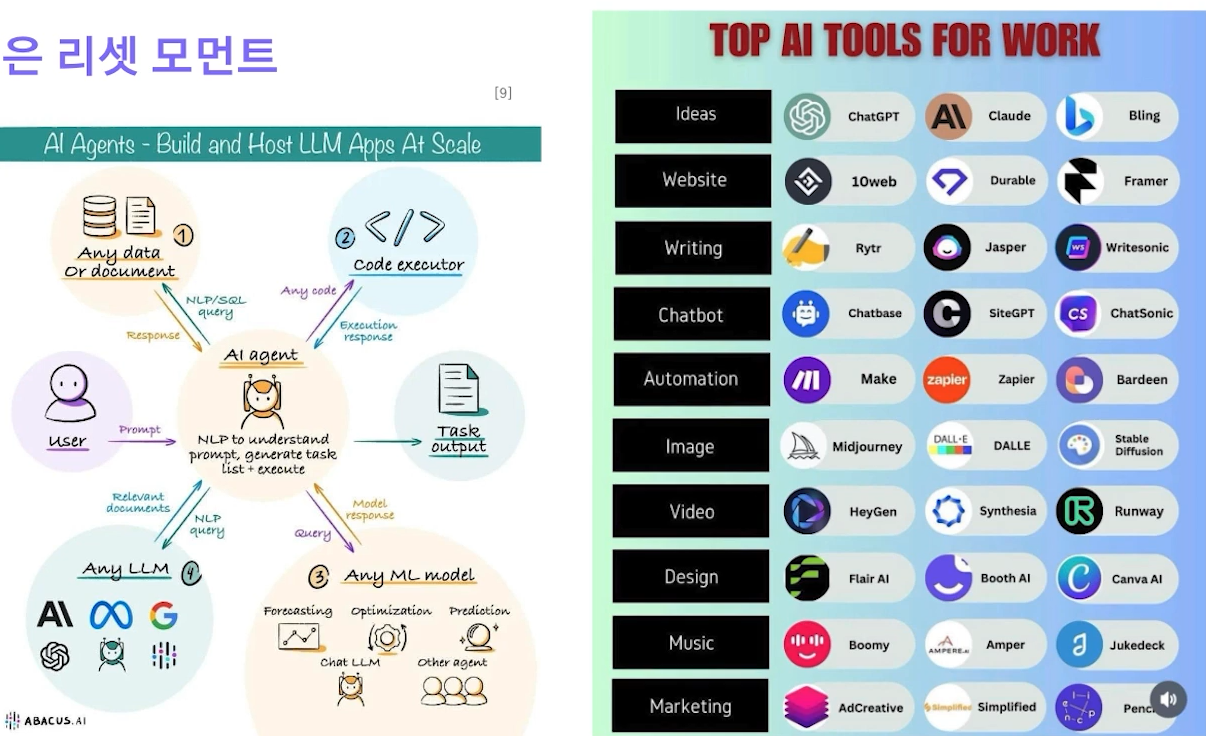
✔️ LLM은 리셋 모먼트
Build and Host LLM Apps At Scale - Joel Joseph - Medium
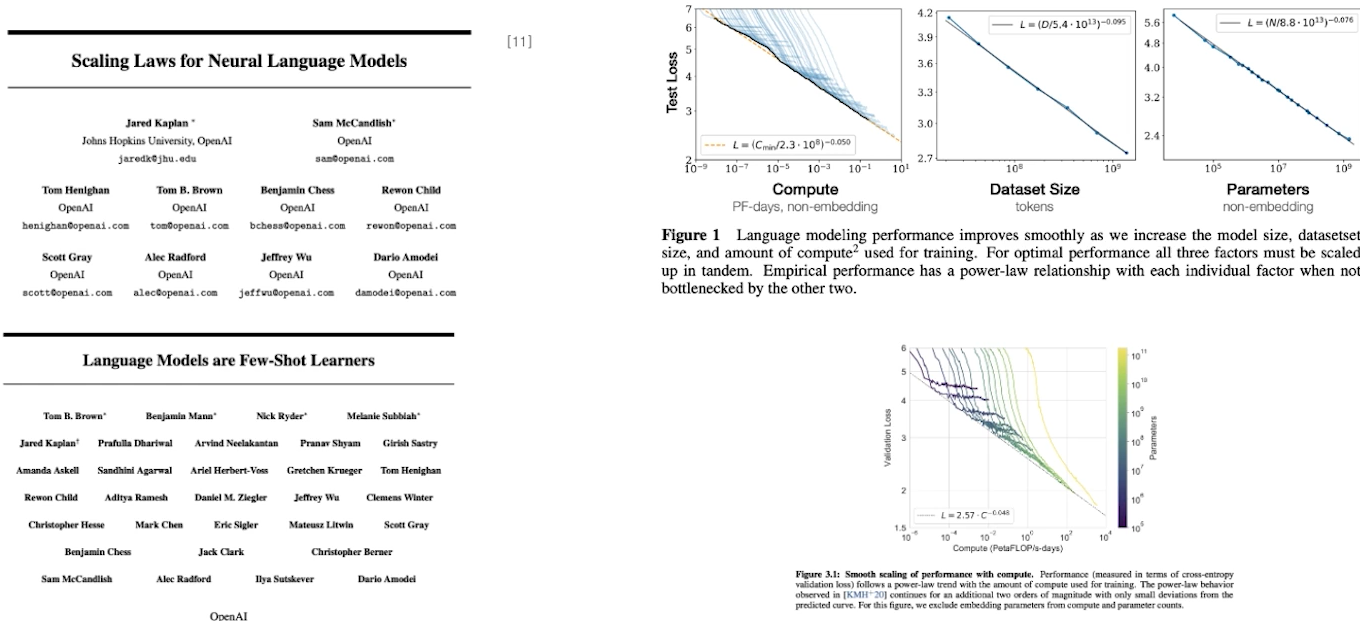
✔️ Scaling Law
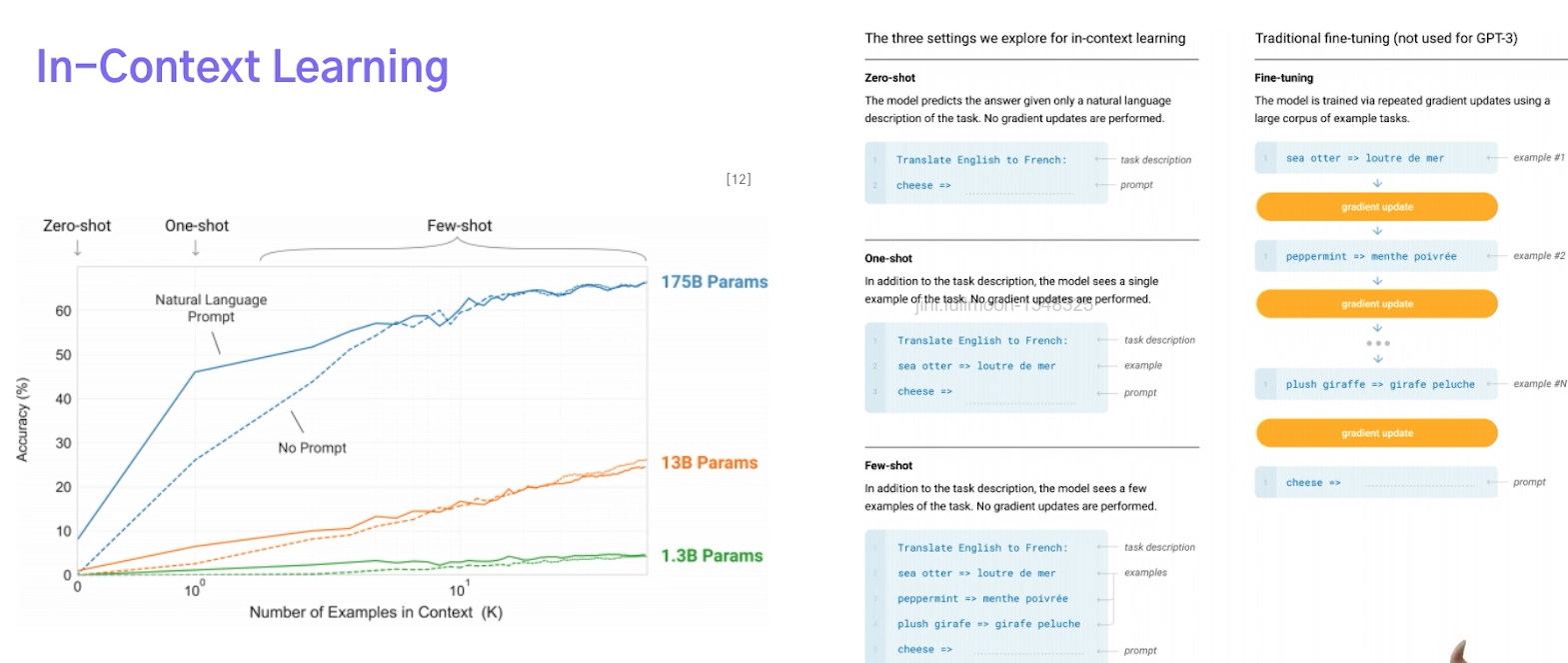
✔️ In-Context Learning
✔️ 특정 크기를 기점으로 급격한 상승
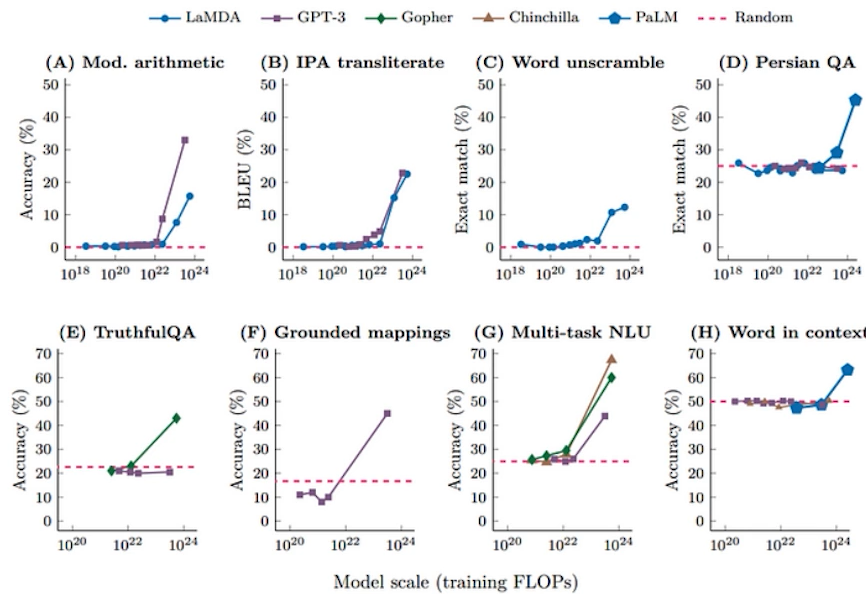
창발성 ! 모델의 크기가 늘어나니 번역뿐만아니라 요약등 다양한것이 가능해짐
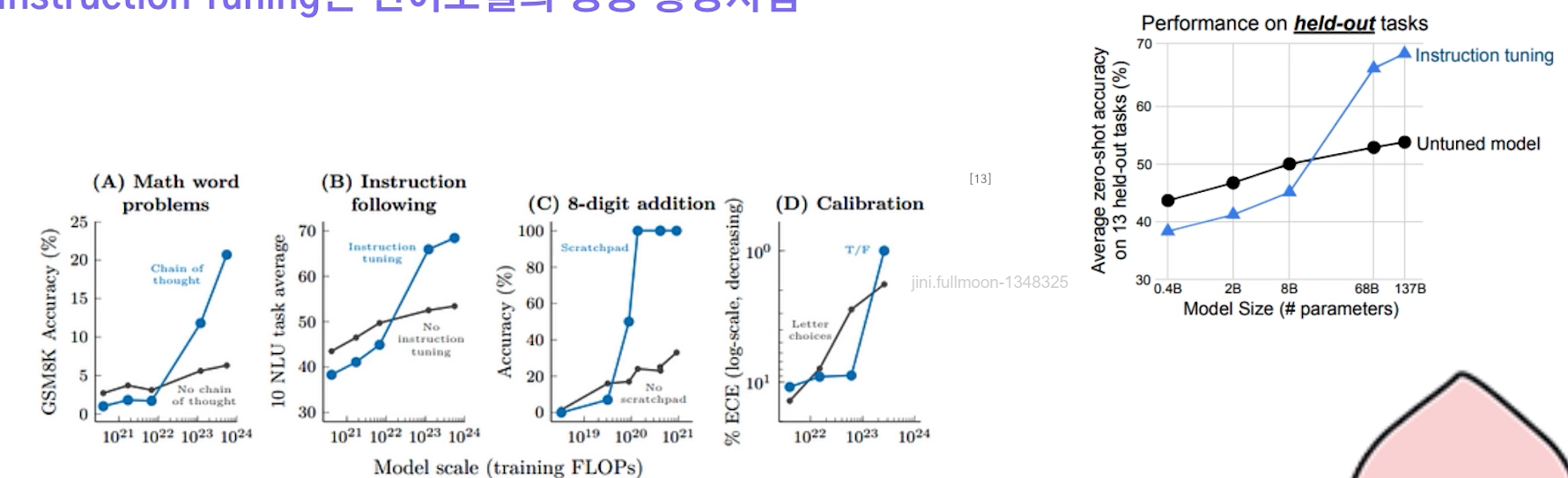
✔️ Instruction Tuning은 언어모델의 성능 향상시킴
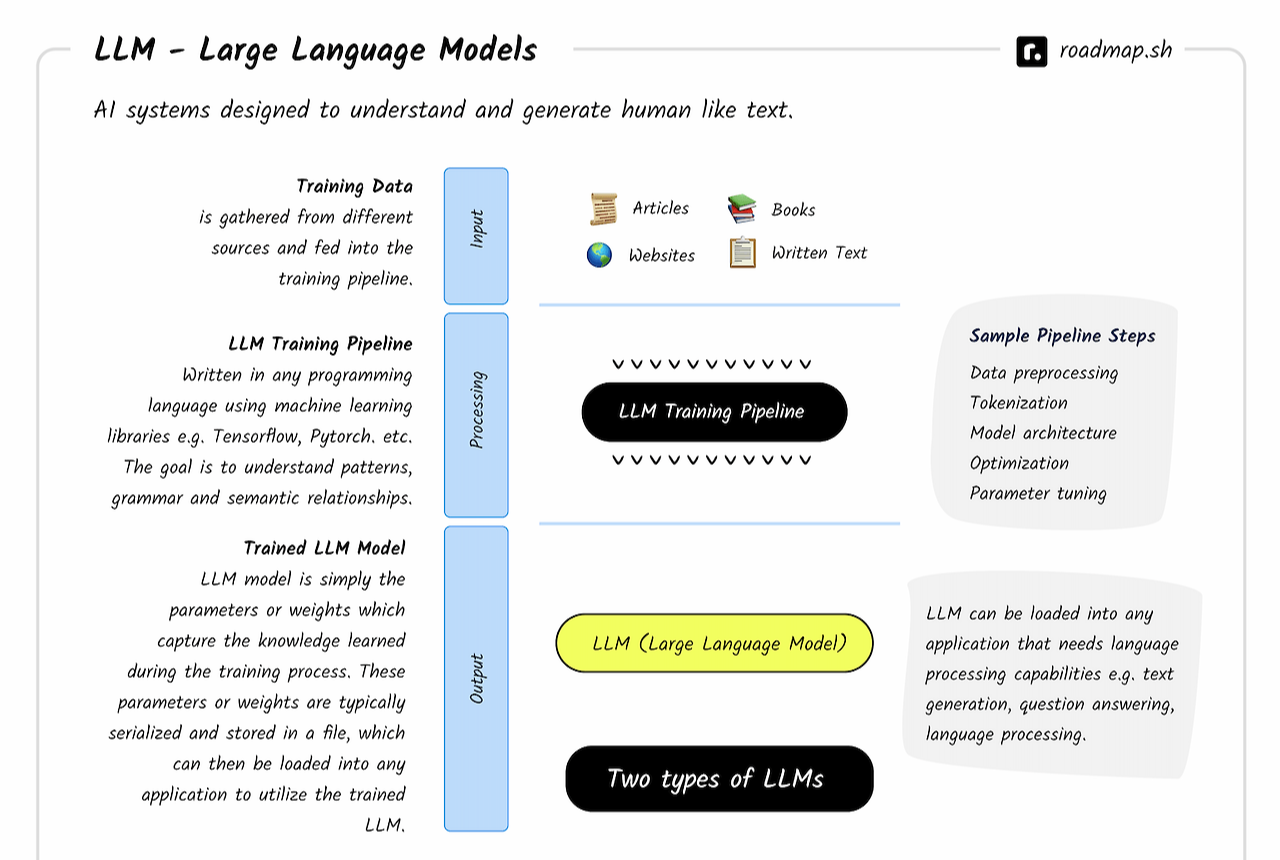
☑️ LLM의 제작 프로세스
✔️ LLM의 재료
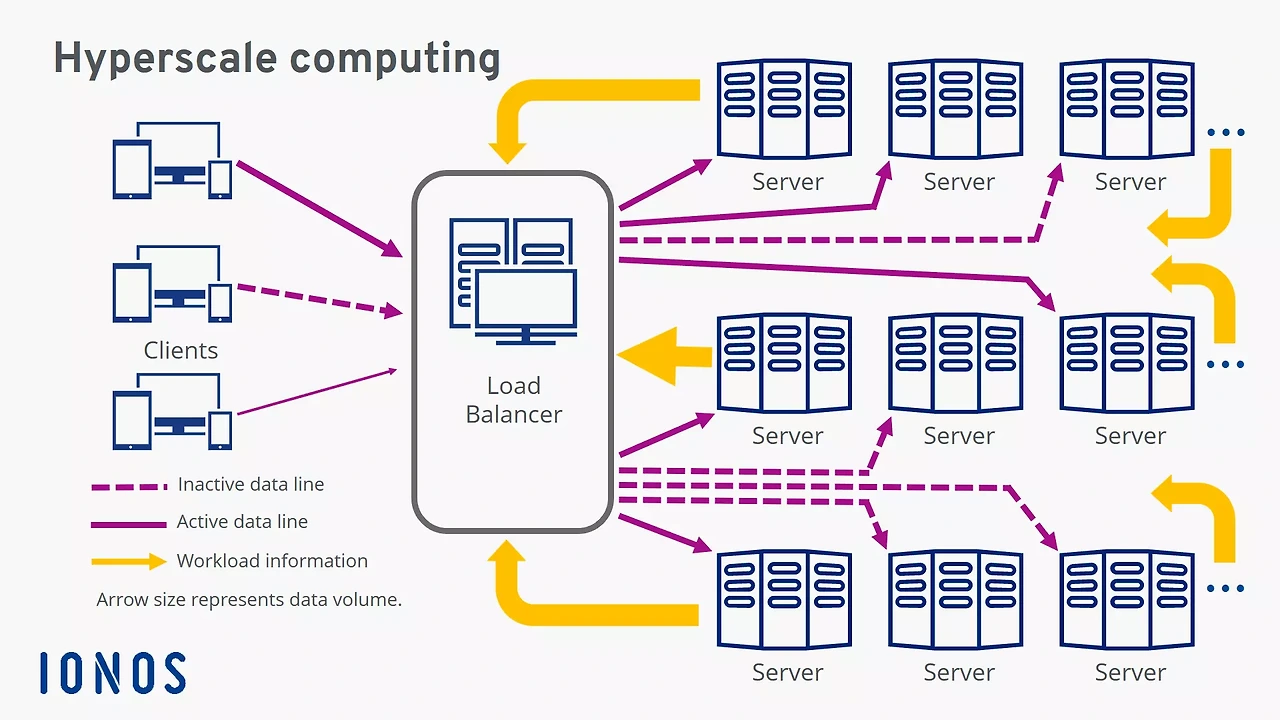
Infra
• Hyper Scale Cloud, Super Computing, Hyper Scale Data Center
•운영 환경 (하드웨어)
• AI+클라우드를 중심으로 비즈니스 패러다임이 이동할 것
Backbone Model
• ChatGPT도 결국 GPT 3.5기반으로 학습
• HyperClova X, SearchGPT도 HyperClova기반으로 학습
What is hyperscale and when is hyperscale computing the right solution? - IONOS UK
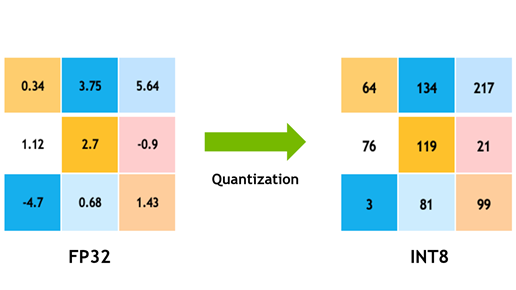
Tuning (비용 효율적인 백본 튜닝 기술)
• 어떻게 경량화 할 것인가?
• 반도체 기술 (행렬 연산 최적화)
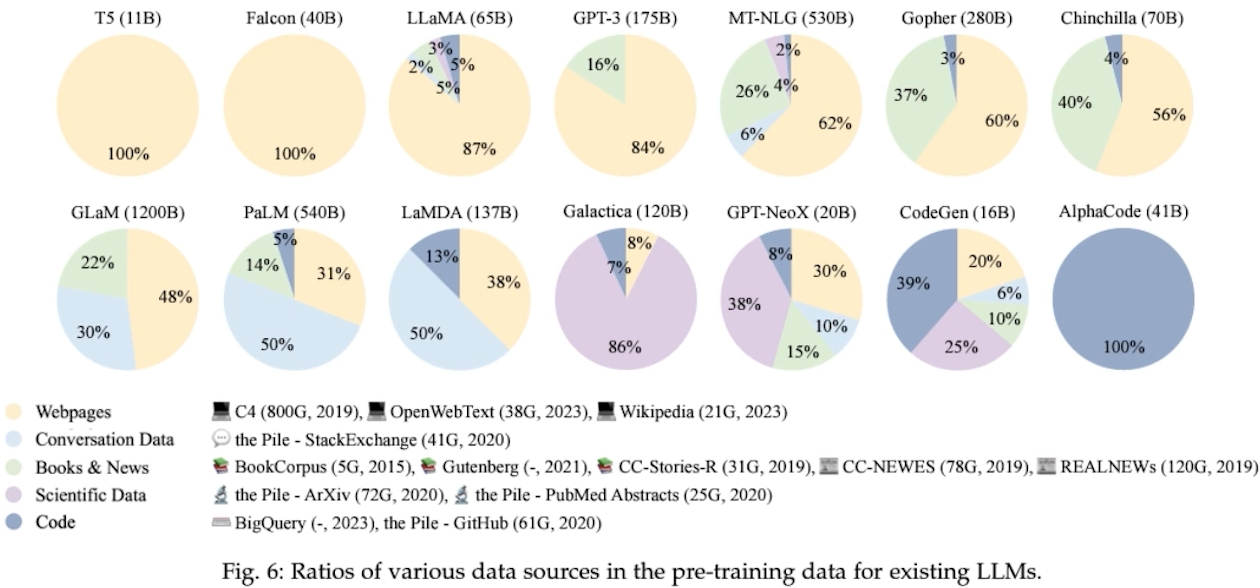
Data (고품질 & 다량의 학습 데이터)
• Prompt, Instruction
✔️ LLM의 데이터 구성
✔️ LLM의 제작 과정 – Data Processing
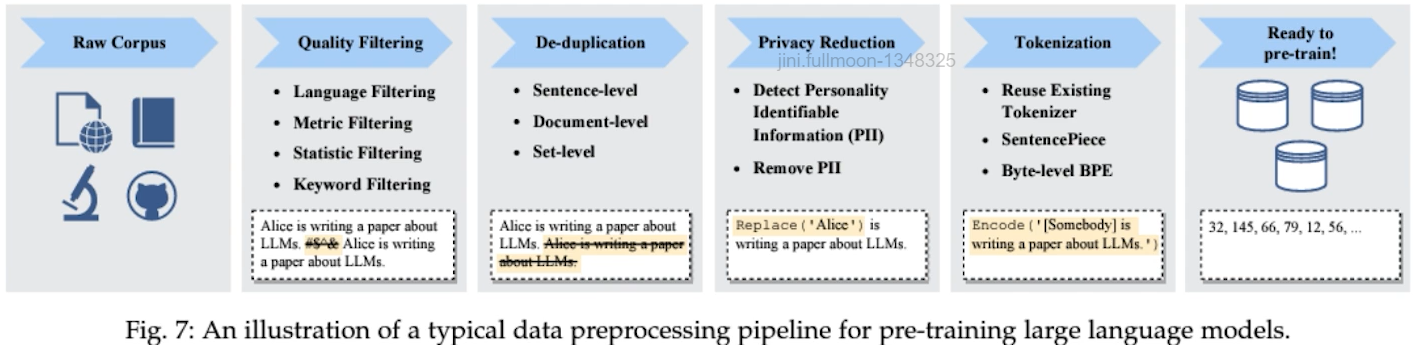
✔️ LLM의 제작 과정 – Pre-training & Supervised Finetuning
Introduction to LLMs - roadmap.sh
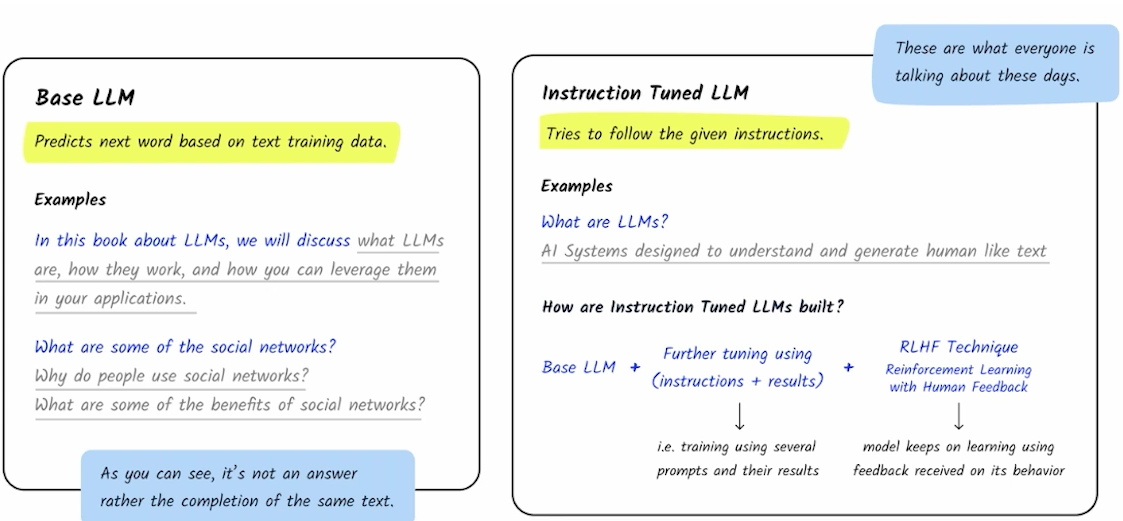
✔️ LLM의 제작 과정 - 결과
✅ Large Language Model의 방향성
☑️ Data & Size
✔️ 데이터 - 모델의 역량을 충분히 활용하고 있을까?
• Scaling Law – 정말 더 크게?
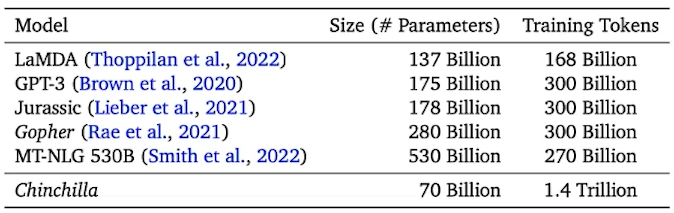

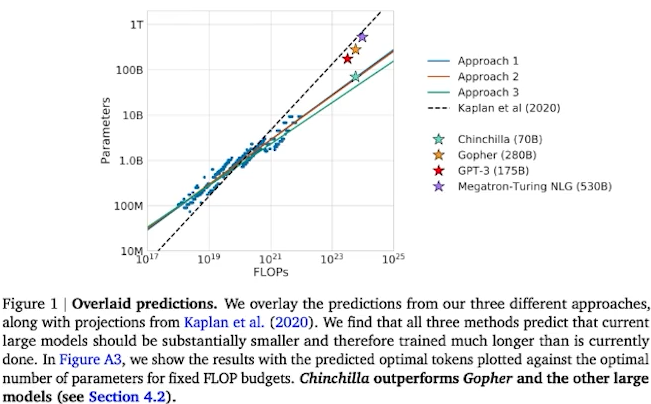
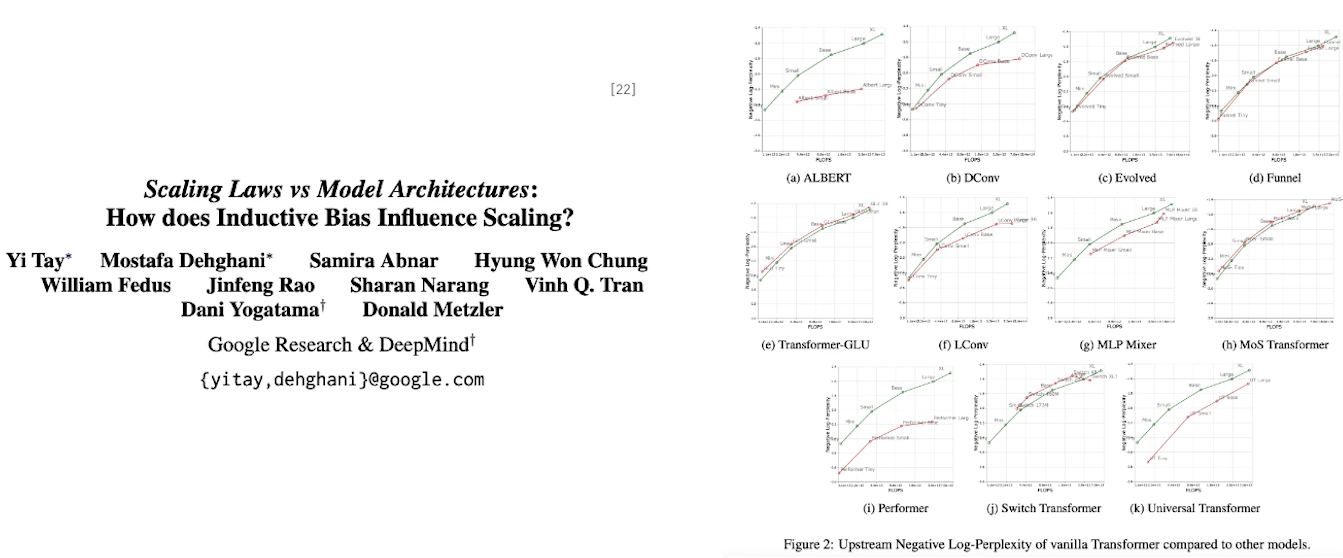
✔️ 모델링과 데이터 중 어떤 것이 더 중요할까?
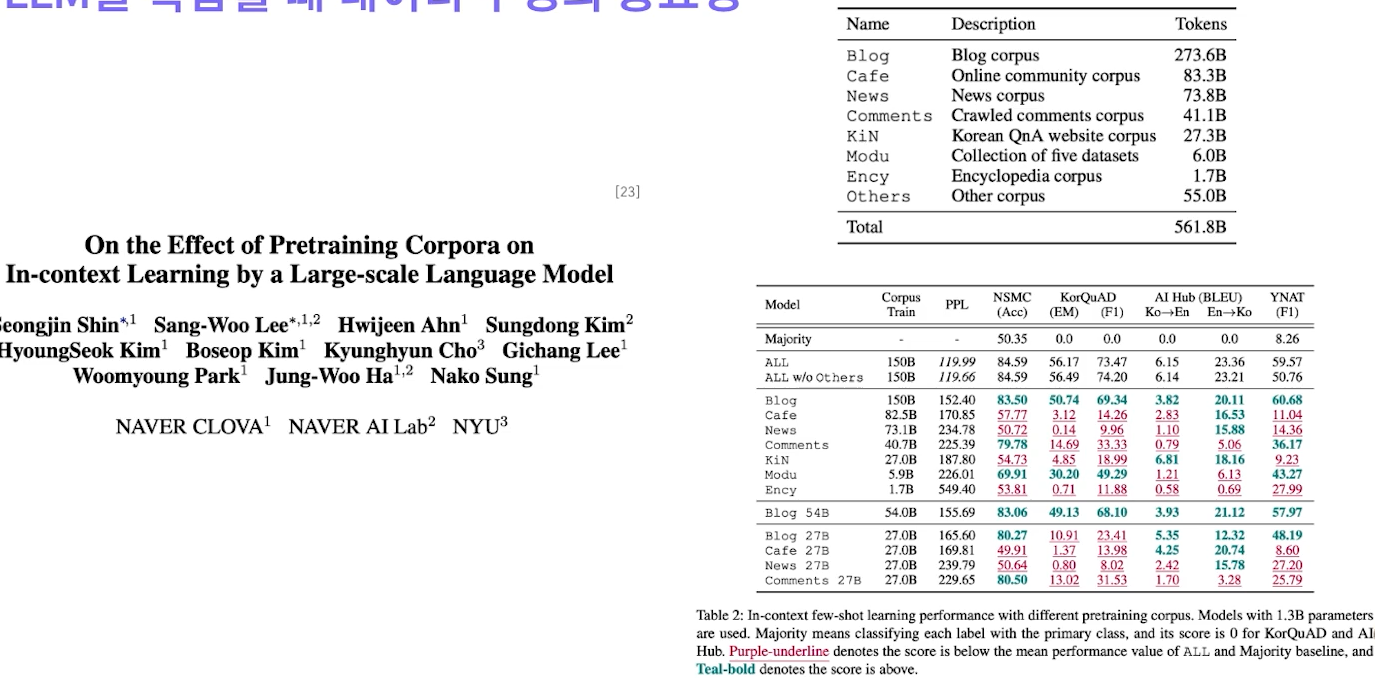
✔️ LLM을 학습할 때 데이터 구성의 중요성
✔️ 중요한 것은 사전학습 모델의 크기!
슈퍼컴 필요없는 소형 언어모델 'sLLM' 급부상 < 산업일반 < 산업 < 기사본문 - AI타임스

✔️ 중요한 것은 사전학습 모델의 크기!
☑️ Multimodal
✔️ Vision and Language
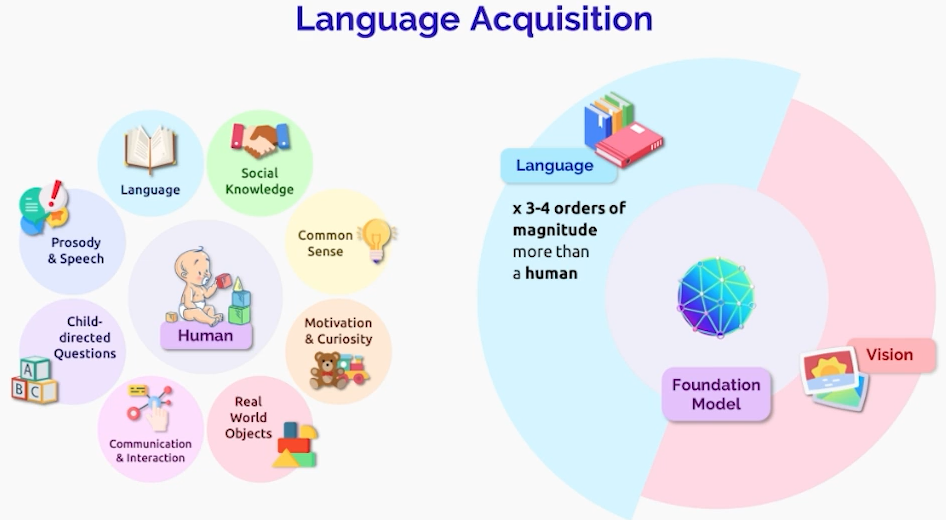
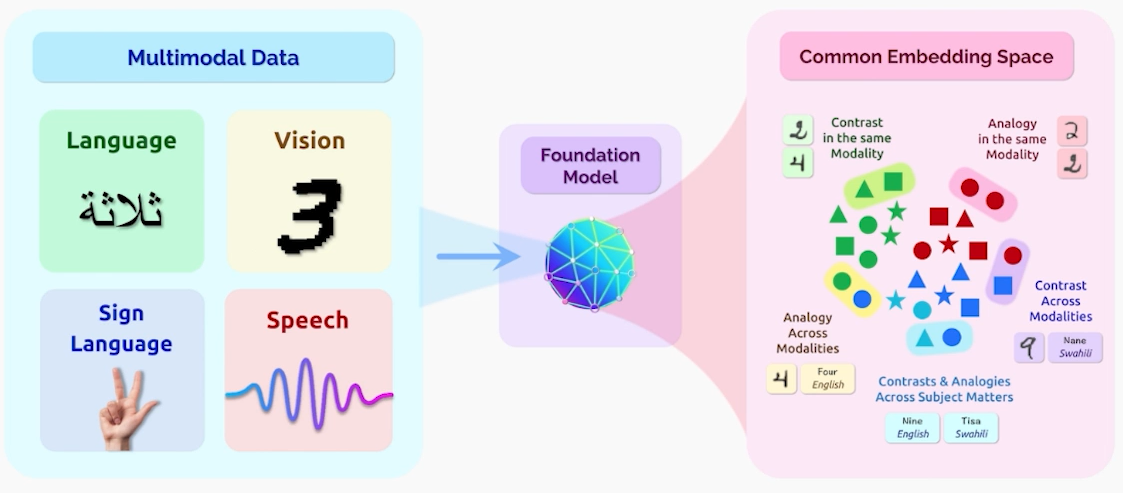
✔️ PaLM-E: Google Research가 보유한 PaLM을 Robot과 멀티모달 학습에 적용

✔️ Kosmos-1 & 2 : Microsoft가 Multimodal Large Language Model 공개
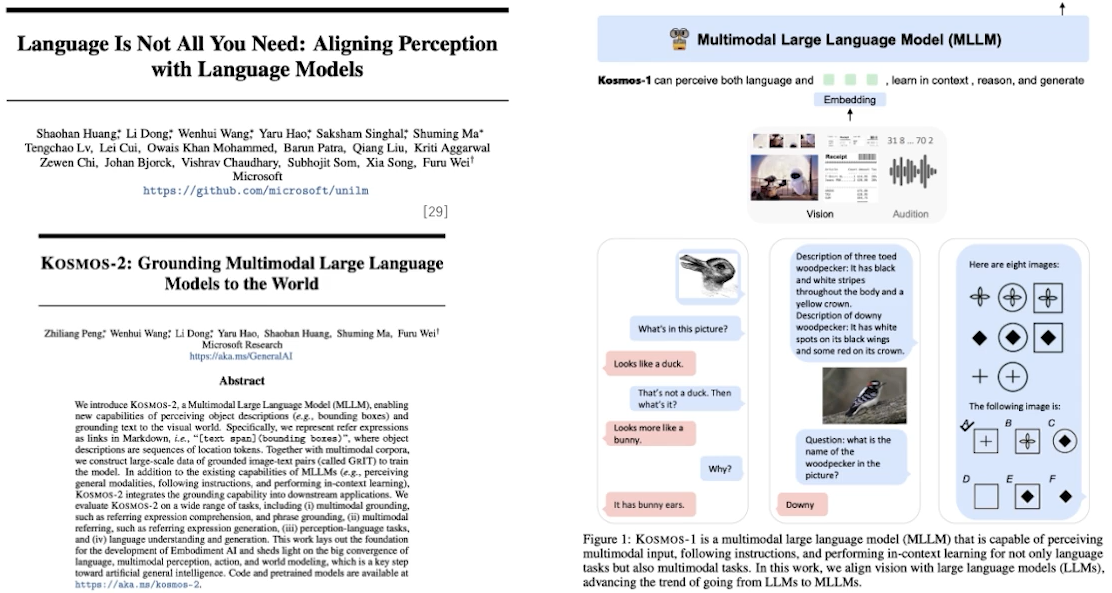
✔️ GPT-4: Open AI가 ChatGPT 릴리즈 후, 반년도 안되어 GPT-4 공개
✔️ Gemini: Google Deepmind의 새로운 Multimodal Model
✔️ Meta의 “IMAGEBIND” = One Embedding Space To Bind Them All
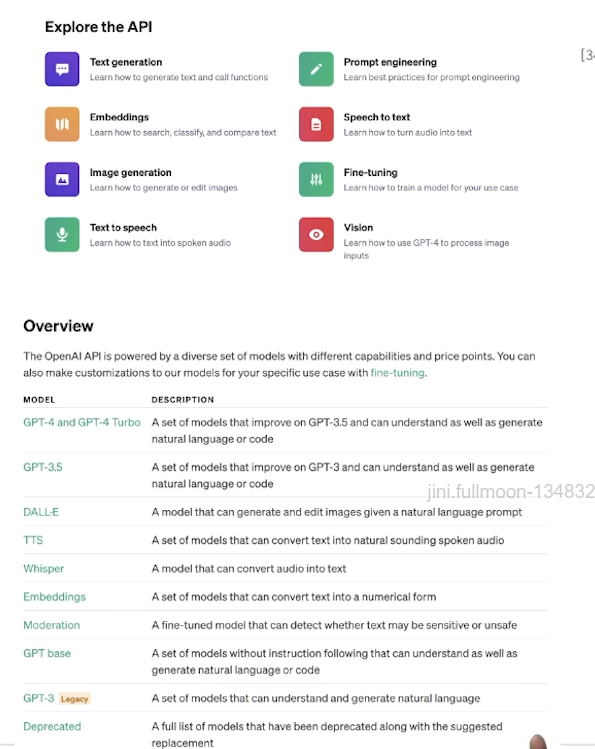
✔️ OpenAI Family
☑️ Multilingual
(다국어 처리)
✔️ Open Source 진영

Palm2 / 한국과 일보어에 신경을 쓰고 있음
✔️ OpenAI
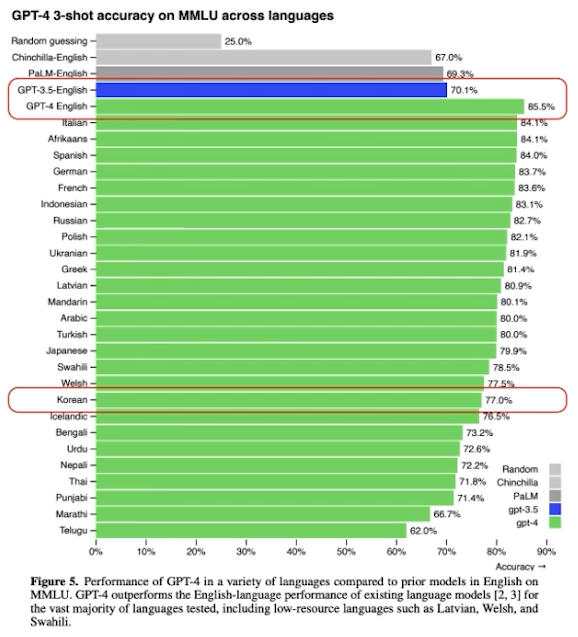
✔️ Generative Model, Synthetic Data의 비중 상승 추세
Is Synthetic Data the Future of AI?
The diverse world of generative AI - Tech in Asia
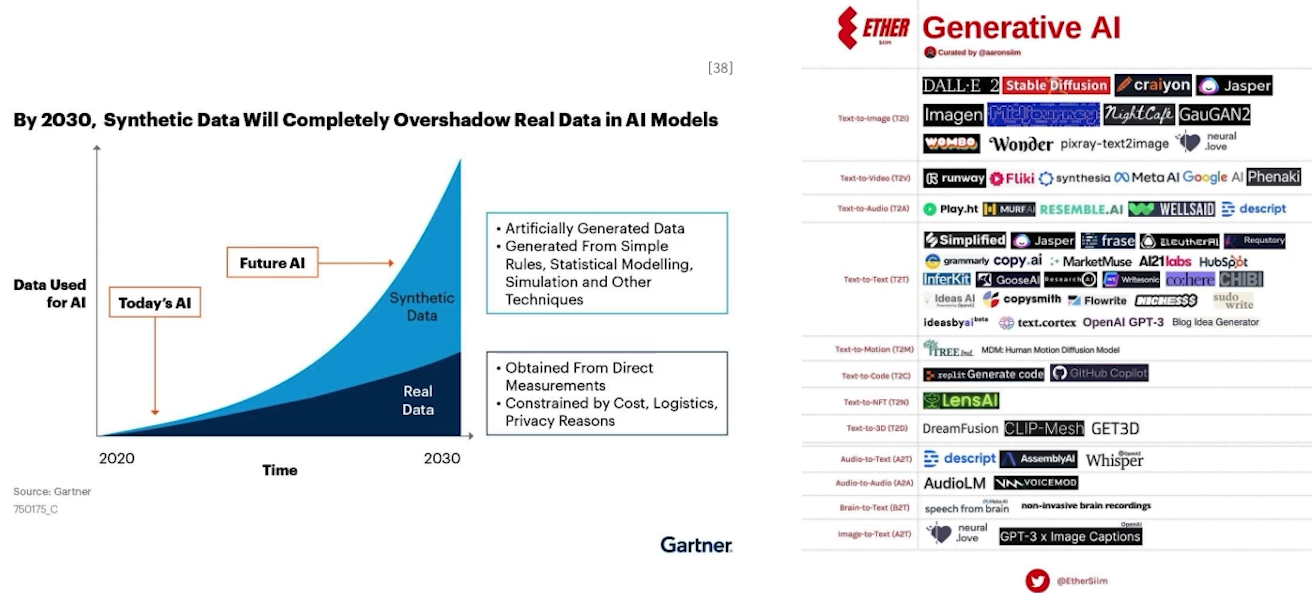
✔️ 심지어 강력하고 사람보다 우수한 Case가 발생
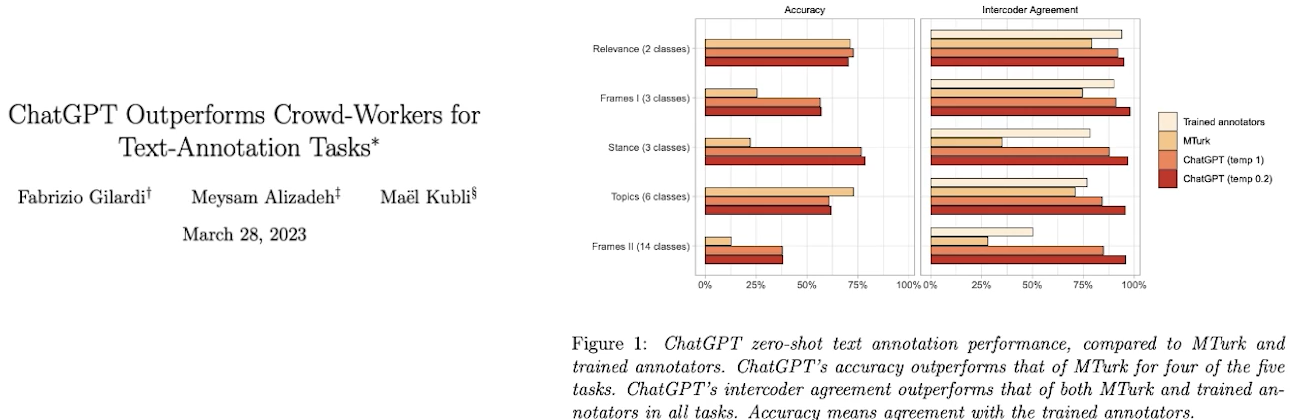
✔️ LLM을 이용한 레이블링 성능의 변천사

☑️ Domain Specialized
✔️ Domain Specialized
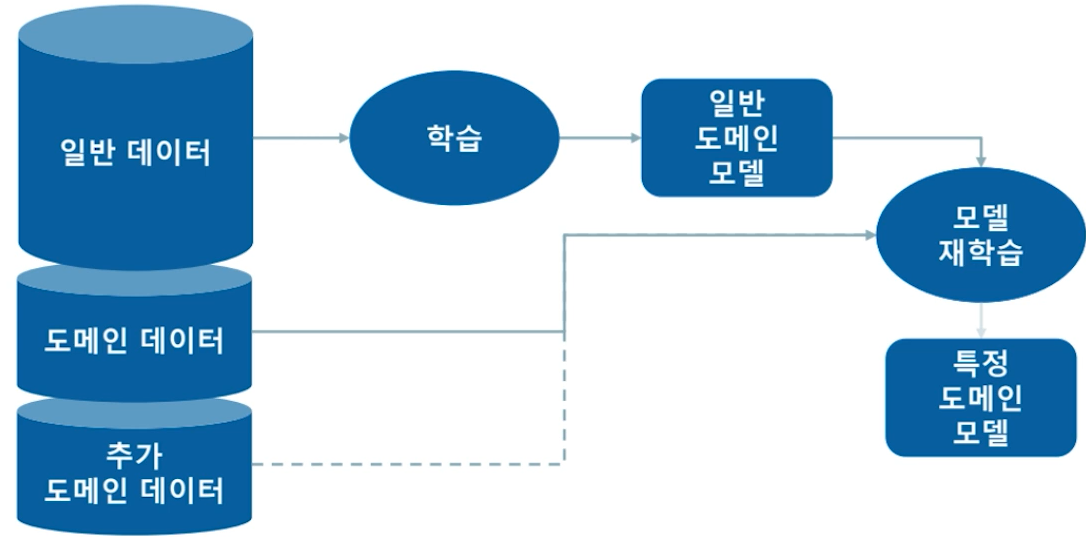

☑️ Evaluation
✔️ Evaluation
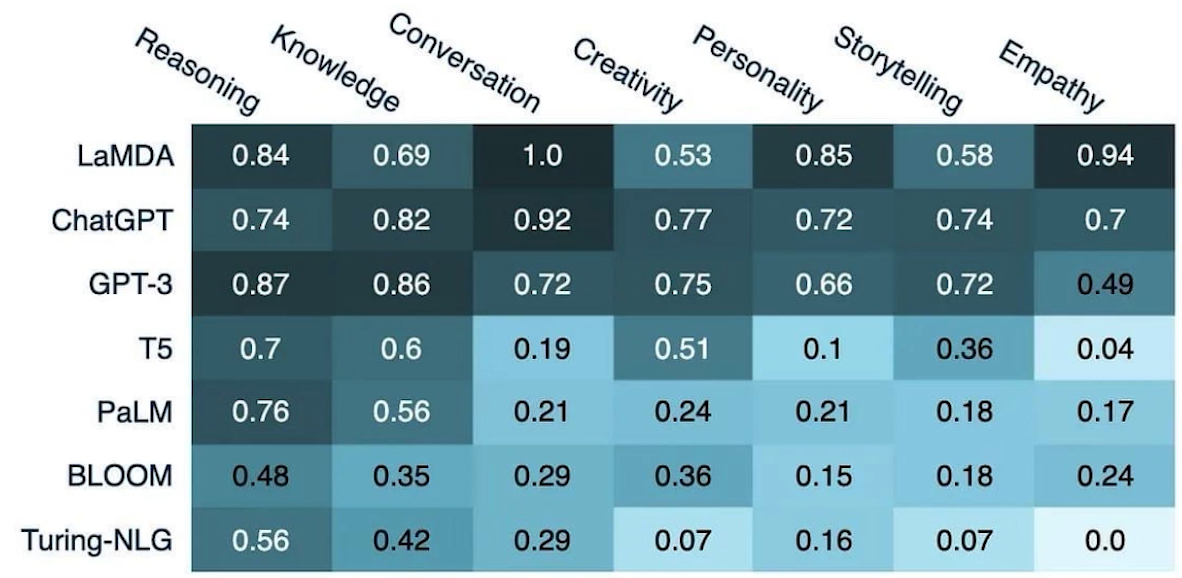

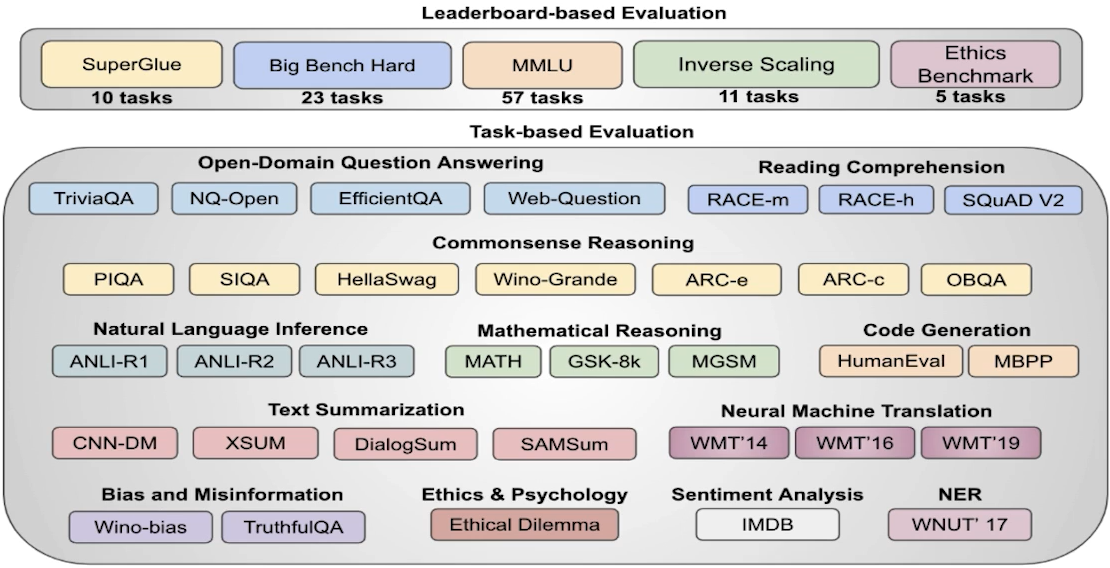
✔️ GPT-EVAL
LLM을 평가 !
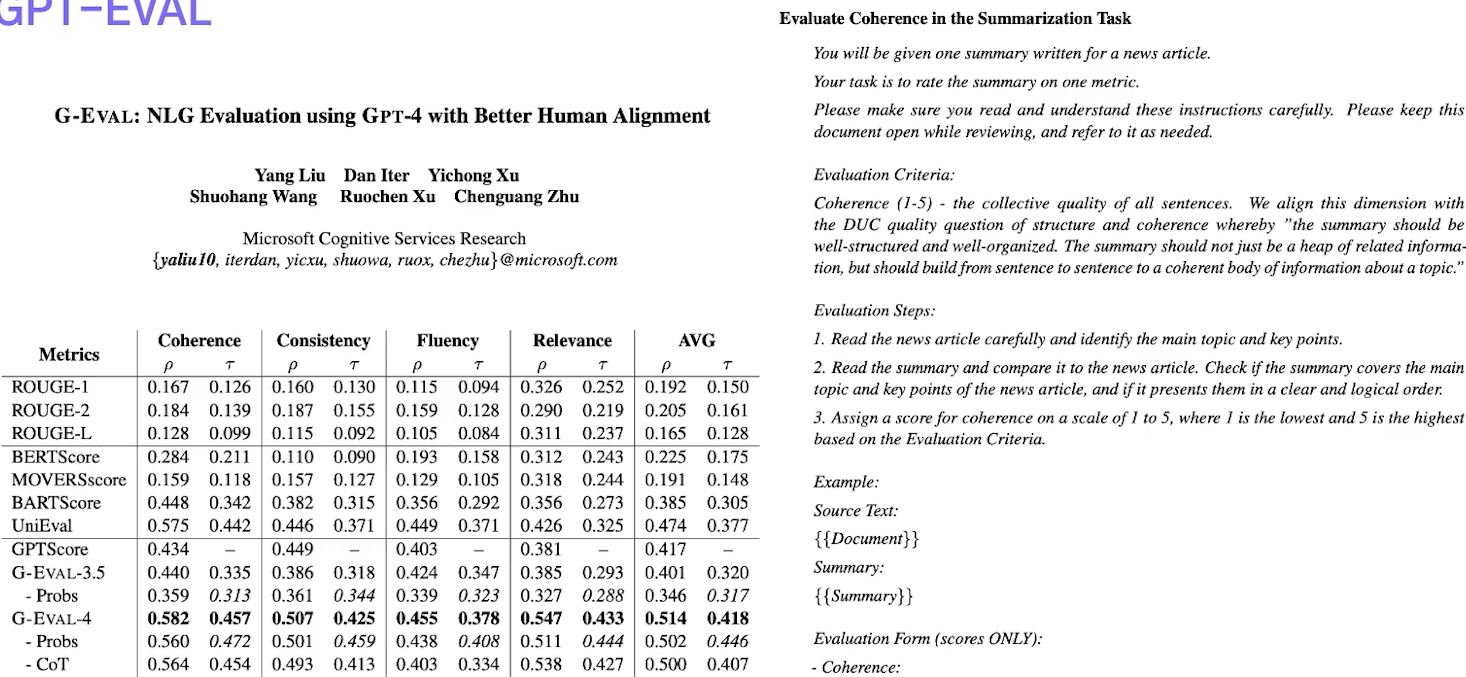
✔️ LLM-Eval

☑️ Prompt Engineering
✔️ Prompt Engineering
• Prompt: LLM으로부터 사용자가 원하는 결과를 도출하기 위한 Input 혹은 Instruction
• Prompt Engineering: 대화형 AI가 생성하는 결과물의 품질을 높일 수 있는 prompt 입력 값들의 조합을 찾는 작업
[IT TREND] 프롬프트 엔지니어링, AI라는 도구를 잘 사용하는 방법

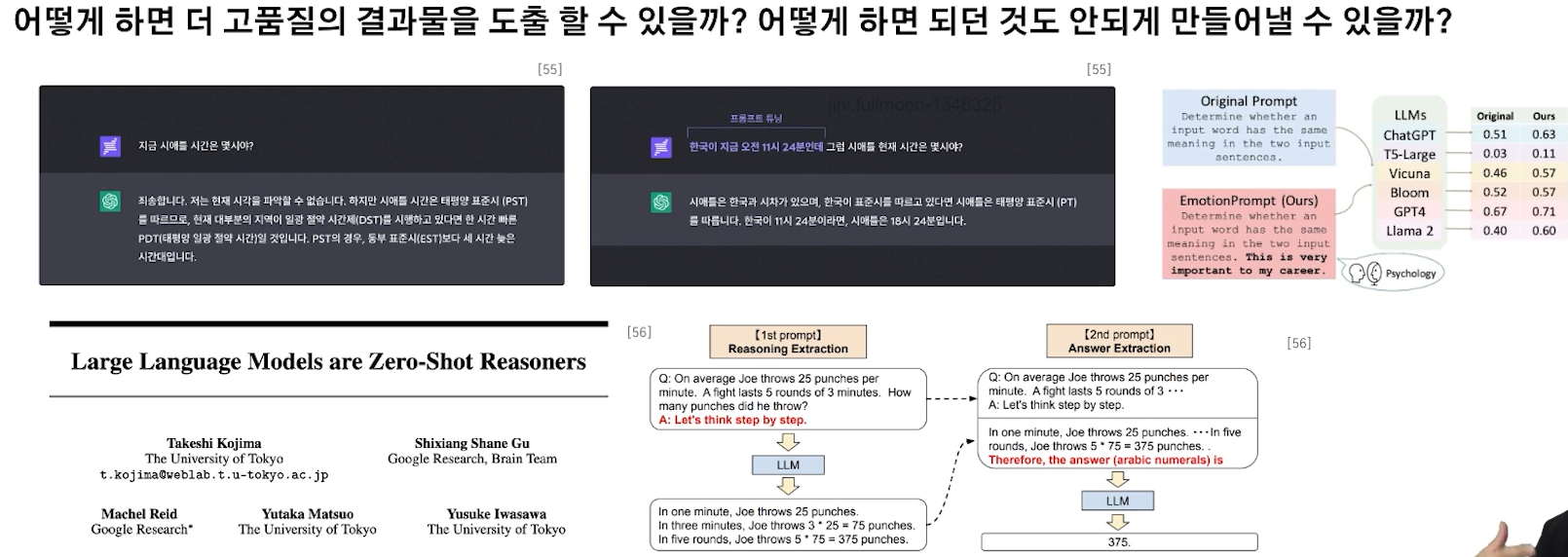
✔️ Prompt Engineering에 대한 Revisiting
단순히 LLM이 보유하고 있는 내재된 능력치를 발굴하는 것은 Prompt Engineering이 아닌 Prompt Discovering이라고 생각 → 논문 1개로 끝!

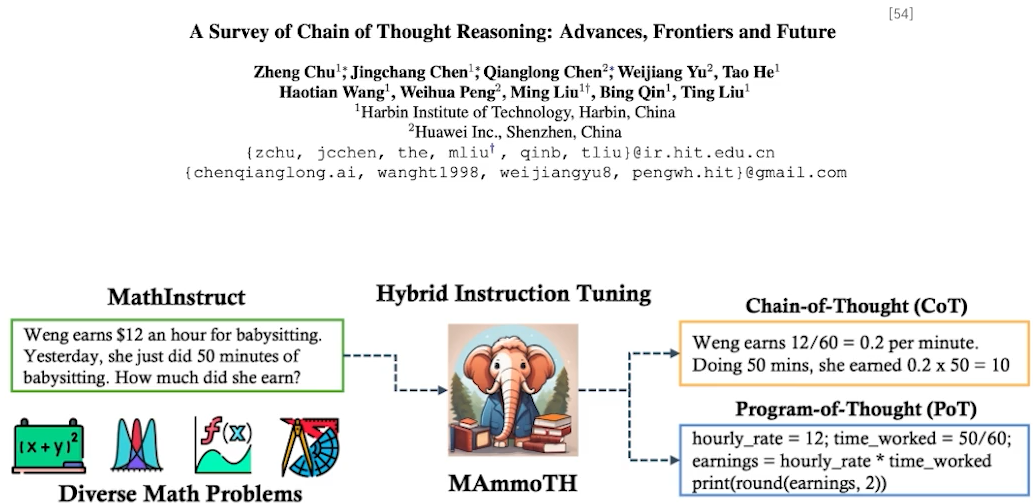
✔️ Chain-of-thought prompting (COT)
•단지 답변을 내놓기 위한 것이 아닌, 답변에 도달하는 과정을 학습시키는 것을 목적으로 함
•사람의 생각의 흐름을 함께 학습 시킴
• PaLM을 학습할 때 추리(Reasoning) 관련 기존 데이터셋을 확장 시켜 중간 논리를 설명한 부분을 넣었더니, 성능이 확연히 오름

✔️ Optimization, Tuning
✔️ Prompt Manager (Cross Function Modality)
Prompt를 발굴하는 것도 중요하나 개별적인 모달리티를 연결하기 위한, Prompt Manager기술이 중요해 질 것 => 이것이 결국 서드 파티를 만드는 핵심
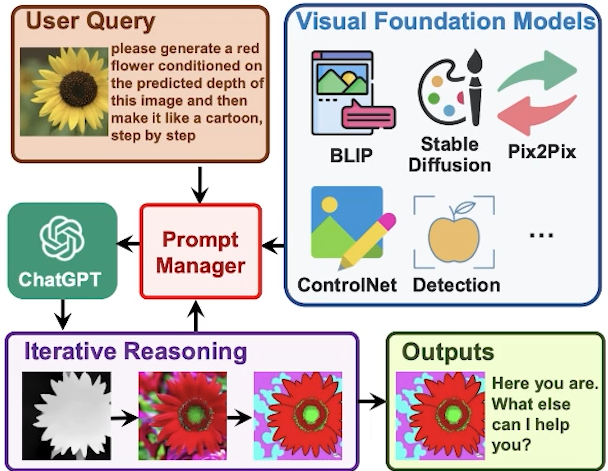
각각의 모듈을 호출!
✔️ Prompt Manager (API Manager)

✔️ Function Call
•모델이 API 호출 입력으로부터 함수 호출 시점을 파악해내고, 함수 호출에 필요한 파라미터 등의 정보를 JSON 형태로 내보낼 수 있게 하는 것
• ChatGPT API 호출을 통해 원하는 함수를 적절한 인자와 함께 호출하는 것이 가능

✔️ Prompt Engineering (Learning)
• Parameter Efficient Fine-Tuning (PEFT) -> P-Tuning (Prompt Learning), LoRA (Adapter)
=> 모델의 일부 파라미터만을 튜닝함으로써 모델의 성능을 적은 자원으로도 높게 유지하는 방법론
Guiding Frozen Language Models with Learned Soft Prompts
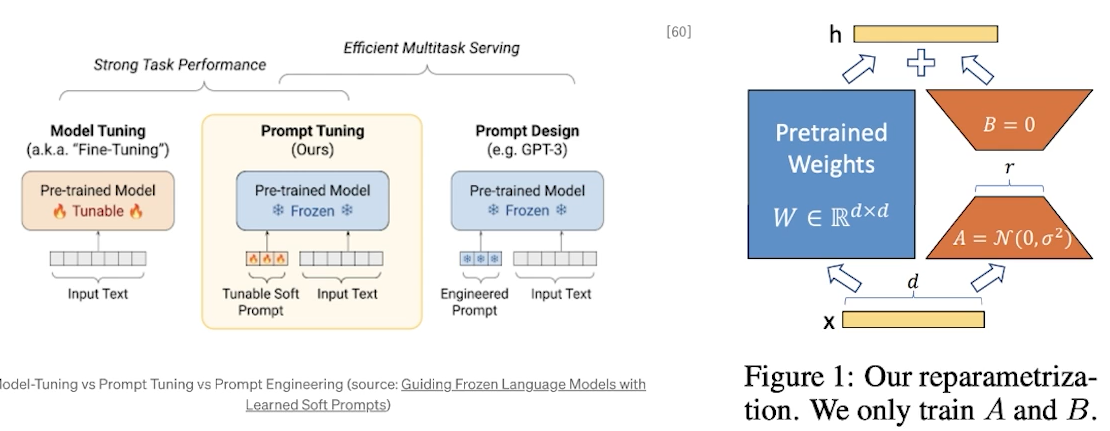
for 도멘인 특화, 언어를 전이
✔️ Prompt Parameter Tuning (PPT)
[IT TREND] 프롬프트 엔지니어링, AI라는 도구를 잘 사용하는 방법

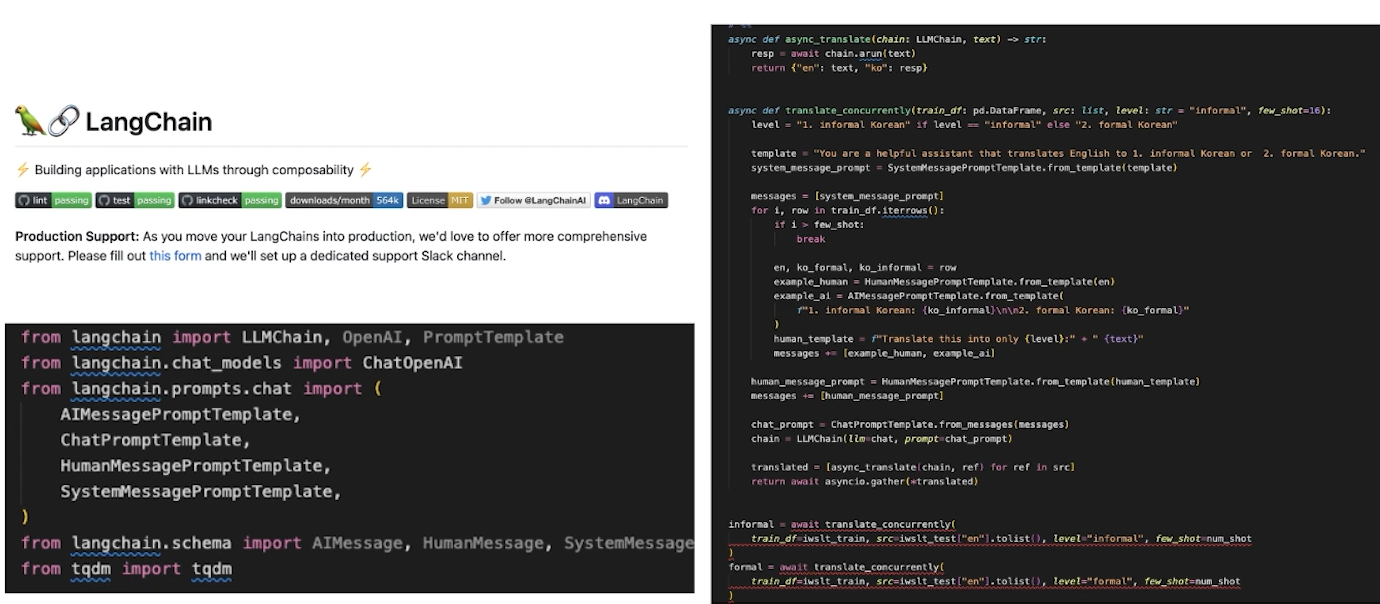
✔️ Automatic Curriculum
• “Goals”만 설정하면 달성을 위해 필요한 것을 자동으로 실행
=> 실수를 스스로 수정하는 ‘자율반복(autonomous iterations)’ 기능을 사용해 결과물을 생성
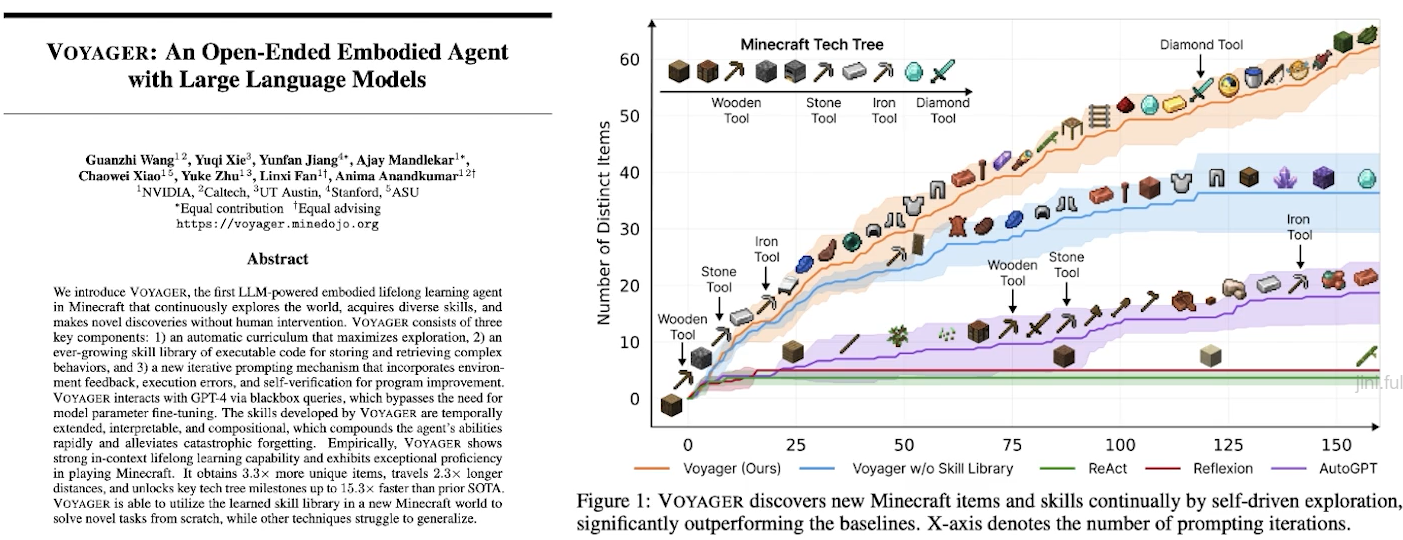
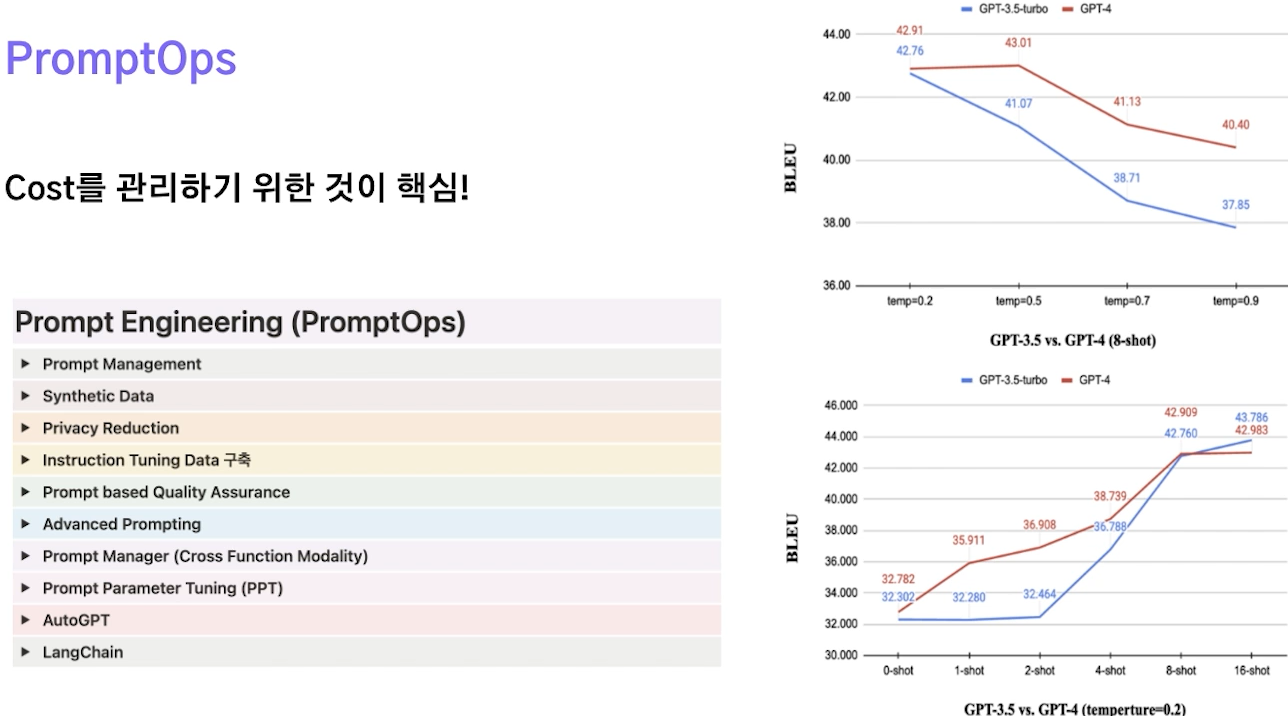
✔️ PromptOps
☑️ 3rd Party Platform
✔️ Prompt Engineering -> 3rd Party Platform (LLM Applications)
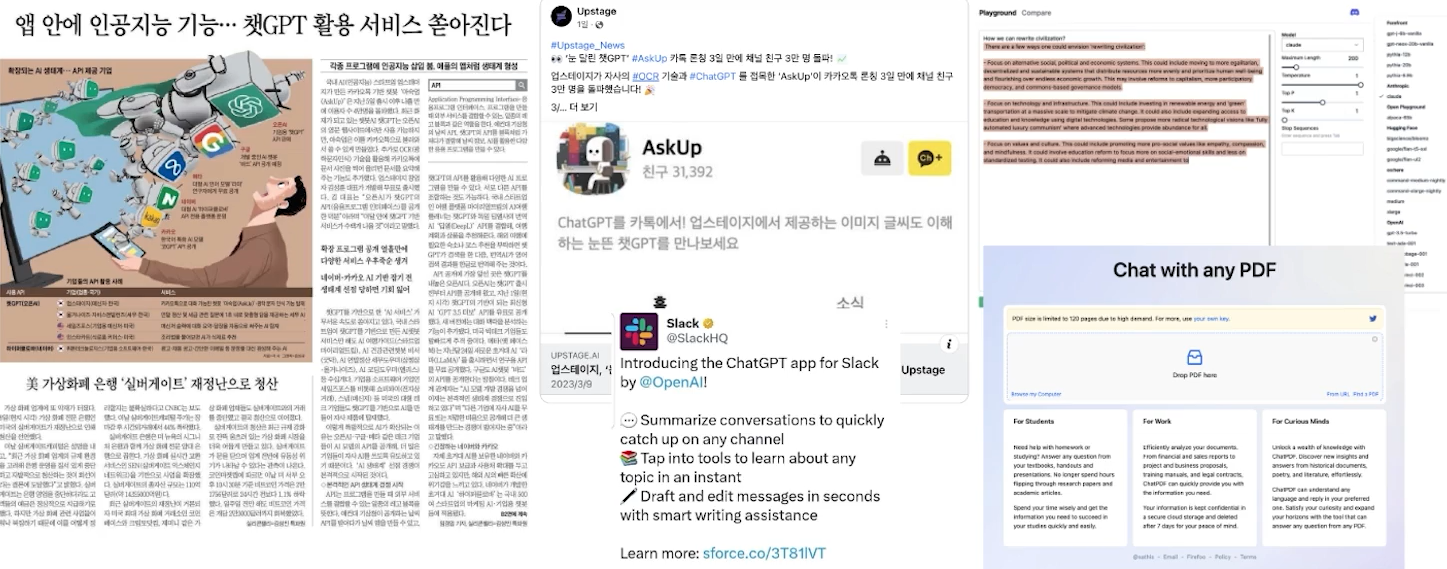
✔️ 3rd Party Platform

✔️ Prompt Engineering -> 3rd Party Platform -> Private AI
SAI Notes #08: LLM based Chatbots to query your Private Knowledge Base.
Building a memory layer for GPT using Function Calling | by Simon Attard | Medium
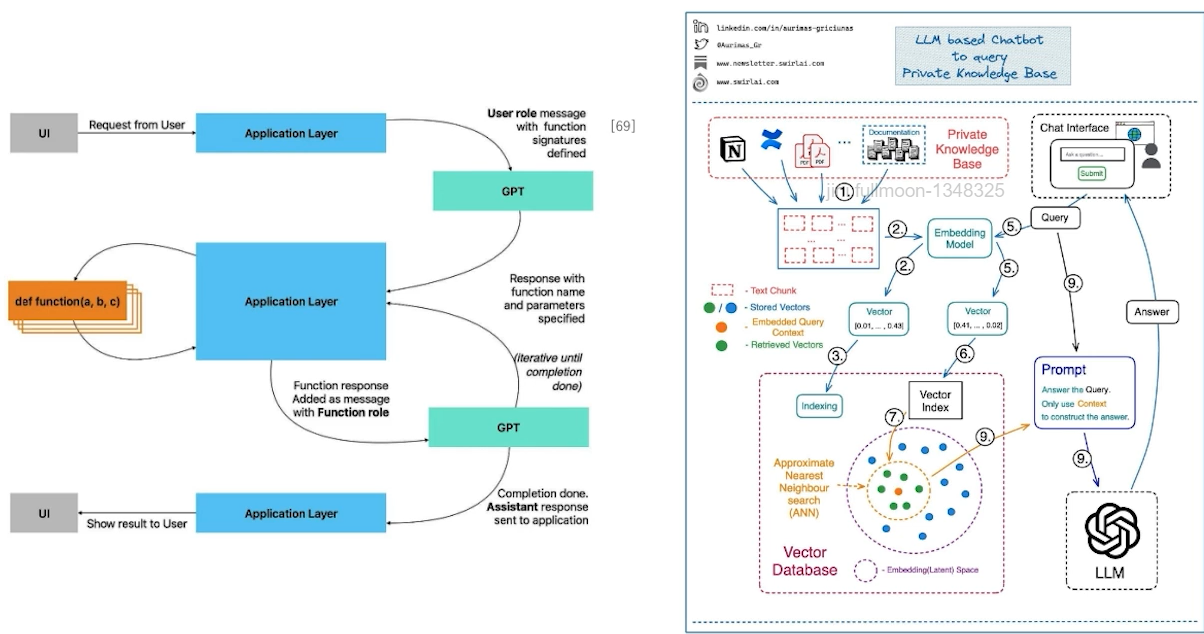
✔️ DevOps -> MLOps -> LLMOps (FMOps)
[IT TREND] FMOps, LLM 시대의 AI 앱 개발 방법

☑️ Open Source
✔️ Open Source
• GPT3 파라미터 크기인 175B까지 모델과 코드 오픈 됨
•그러나 어차피 공개를 해도 돌릴 수 있는 곳이 얼마 없음
• Eleuther AI는 Big Model 민주화를 꿈꾸는 곳
• Huggingface도 마찬가지. BigScience 그룹의 움직임
메타, 언어 모델 OPT-175B 무료 공개 < 산업일반 < 산업 < 기사본문 - AI타임스
bigscience/bloom · Hugging Face
✔️ 내 컴퓨터에서 LLM을 돌릴 수 있는 시대

✔️ 내 컴퓨터에서 LLM을 돌릴 수 있는 시대
GitHub - nlpai-lab/KULLM: ☁️ 구름(KULLM): 고려대학교에서 개발한, 한국어에 특화된 LLM
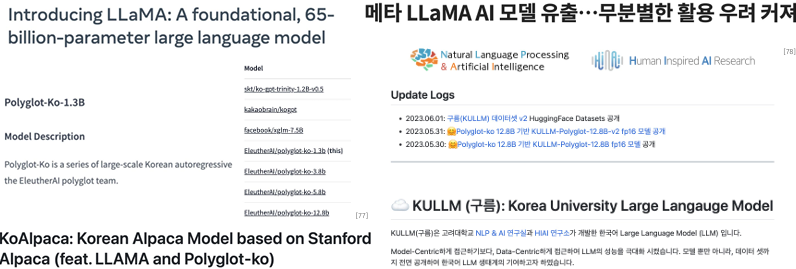
✔️ Open Source LLM Space

✔️ Open LLM Leaderboard
Open LLM Leaderboard - a Hugging Face Space by open-llm-leaderboard
`메타` 제친 K스타트업… LLM 성능 1위 - 디지털타임스
☑️ To be
Timeline History of Large Language Models - Voicebot.ai
(16) LinkedIn
Preoccupy
•선점해야 (First Mover)
Rapid Adaptation
•검색의 패러다임이 변함
•주도권이 AI에서 사용자에게로
•키워드방식에서 Instruct 방식으로
Collaboration
• Infra 영역 (NAVER X Samsung)
• Platform 영역 (MS X OpenAI)
• B2B2C
• Academia
• Evaluation
• Scaling Law
✔️ At a Glance
•잘 활용을 하자
•빠르고 선점해야 함. 그러면서 독자적인 것이 필요
•미래의 LLM Research를 잘 대비하자
• SOTA 의미 없다
• LLM으로 인하여 Converge되는 Task를 잘 분간해야
• Real-World에서 사용할 수 있고, 도움이 되는 기술인지 아닌지로 논문 및 연구는 나뉠 것
• LLM의 명확한 약점을 공략해라 (Reasoning, Commonsense, Hallucination, Expert Knowledge, Ethics)
•정신 똑바로 차리고, 잘 따라가야 함. 최신 트렌드에 굉장히 예민하고 민감해야 함
'04_NLP(Natural Language Processing)자연어처리 > LLM' 카테고리의 다른 글
| LLM 기반 Data-Centric NLP 연구 (2) | 2025.02.06 |
|---|---|
| Large Language Model의 근간 이론들 (1) | 2025.02.06 |
| 사전학습 기반 언어모델의 한계점 및 방향성 (1) | 2025.02.06 |
| 문맥기반 언어지식 표현체계 이론 Ⅱ (0) | 2025.02.05 |
| 의미기반 언어 지식 표현 체계 이론 (0) | 2025.02.05 |