05_CV(Computer Vision)/OCR
Parseq
jiniby
2025. 3. 26. 17:57
728x90
01. ParSeq란?
ParSeq(Permuted Autoregressive Sequence Model)는 대표적인 OCR 인식기 모델로,
Unified STR (Scene Text Recognition) Model에 속합니다.
🔑 Unified STR Model이란?
이미지와 텍스트 특성을 처음부터 함께 종합하여 텍스트 인식을 수행하는 방식
다양한 방향과 형태를 가진 텍스트에서 뛰어난 성능 제공
Two-Stage Ensemble Model과 달리 Vision 모델과 Language 모델이 처음부터 통합됨.
02. 핵심 개념: Permutation Language Modeling (PLM)
PLM은 **모든 가능한 순서(Permutation)**에 대해 학습하여 다양한 방향의 텍스트를 효과적으로 인식하는 방법입니다.

🔖 PLM의 핵심 아이디어
- 문장 길이(T)에 대해 총 T!개의 가능한 순서 존재
- 이 중 일부(K개)만을 랜덤하게 선택해 학습
- AR(Autoregressive) 모델링의 일반화된(generalized) 버전으로 사용됨
- Attention Mask를 통해 Transformer에서 미래 정보(Future token)에 접근하지 못하게 제한하여 AR 모델링을 유지함

03. ParSeq 모델 구조
ParSeq 모델은 크게 두 가지로 구성됩니다:
① ViT (Vision Transformer) Encoder
- 총 12개의 Transformer Layer로 구성됨
- 입력 이미지를 작은 패치(patch)로 분할하여 token화 함
- CLS 토큰과 Classification Head는 포함되지 않음 (문서 분류가 아니라서)
- 모든 출력 토큰이 Decoder의 입력으로 사용됨

② Visio-lingual Decoder
하나의 레이어로 구성되며, Position token, Context token, Image token 입력받음
두 가지 Multi-Head Attention (MHA) 사용:
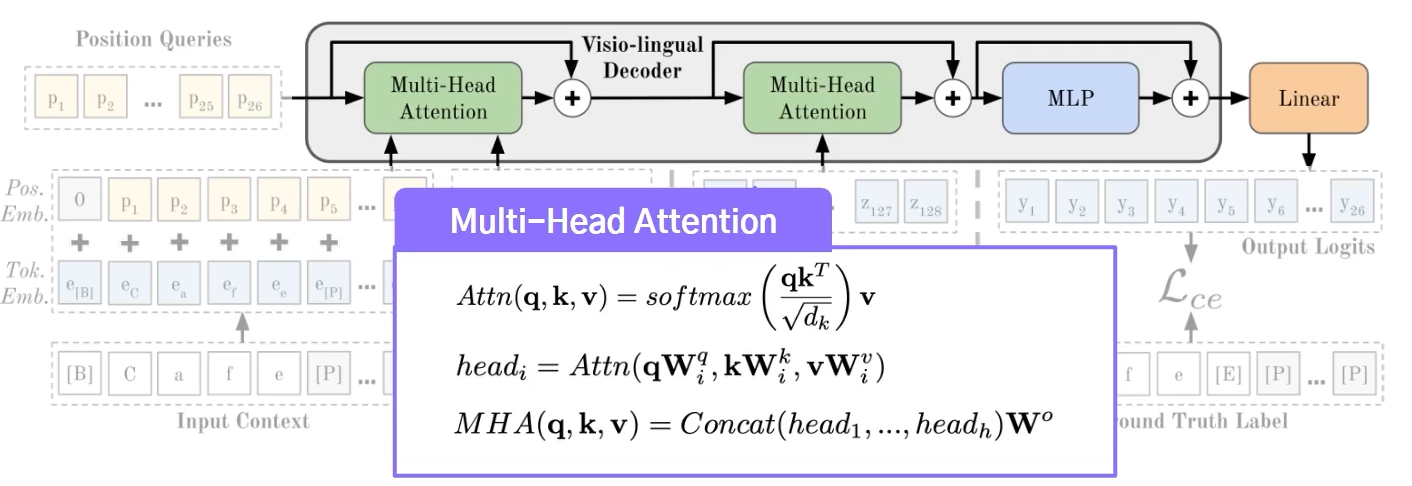
Context–Position Attention (1st MHA):
목표 위치(Position)와 문맥(Context)을 분리해 효과적으로 PLM 학습 가능케 함
Attention Mask를 통해 순서(permutation)에 따른 정보 흐름 제한

Image–Position Attention (2nd MHA):
이미지 특징과 Position 정보 간 Attention 수행
Attention Mask를 사용하지 않음
최종적으로 MLP를 통해 문자 집합의 크기(S)에 맞는 최종 로짓(logit) 출력


04. ParSeq의 학습 방법 (Training PLM)
전체 T!개 Permutation 중 K개만 선정하여 학습 진행
안정적인 학습을 위해 K개는 다음과 같은 방식으로 선정됨:
1개는 Left-to-right permutation ([1,2,...,T])
K/2 - 1개는 랜덤한 Permutation
나머지 K/2개는 앞서 선정한 Permutation의 Flipped Version(반대 방향)
최종적인 손실 함수(Loss)는 선택한 K개의 Permutation의 합으로 계산됨

05. ParSeq의 Decoding 방식
세 가지 Decoding 방식이 존재합니다:
🔖 ① Autoregressive (AR)
- 한 번에 하나씩 토큰을 생성
- 이전 결과가 다음 결과에 직접적 영향
🔖 ② Non-autoregressive (NAR)
- 전체 문장 토큰을 한 번에 생성
- 빠른 속도로 병렬적 처리 가능하지만, 맥락(context) 이해는 상대적으로 낮음
🔖 ③ Iterative Refinement
- AR, NAR로 예측한 결과를 반복적으로 개선(refine)
- 항상 모든 위치를 동시에 고려하여 보다 정확한 결과 도출
06. 실험 및 분석 (Experiment & Analysis)
🔖 Dataset 사용
- 대표적 Synthetic Dataset: MJSynth, SynthText
- Real-world와 유사한 데이터셋: Uber, COCO, ArT 등 다양한 환경에서 평가

🔖 Permutation 개수(K)와 정확도 비교
K=1: (좌→우) 기본 AR 방식 성능 우수하지만 NAR, Iterative 방식 성능 낮음
K≥6: 모든 방식에서 안정적 성능 제공

🔖 다른 모델과의 성능 비교
- ParSeq 모델은 AR, NAR 방식 모두 타 모델 대비 우수한 성능
- 특히 글자가 가려지거나(occlusion), 다양한 방향(orientation) 상황에 강력함
- 비용 대비 효율성(cost-quality trade-off)에서도 뛰어난 성능 제공


07. ParSeq 성능 요약
| 특징 | 설명 |
| 다양한 형태 대응 | PLM을 통해 다양한 텍스트 순서 및 방향에 우수한 성능 |
| 구조의 단순성 | ViT Encoder + Visio-lingual Decoder 구조 |
| 빠른 처리 가능 | NAR 방식은 빠르게 병렬 처리 가능 |
| 정확도 향상 | Iterative Refinement를 통해 높은 정확도 유지 |
🧠 핵심 정리 한눈에 보기
ParSeq 모델 (Unified STR Model)
├─ PLM (Permutation Language Modeling)
│ ├─ 다양한 텍스트 방향 학습
│ └─ Attention Mask 활용해 정보 흐름 제한
│
├─ 모델 구조
│ ├─ ViT Encoder (이미지 특징 추출)
│ └─ Visio-lingual Decoder (텍스트와 이미지 특징 융합)
│ ├─ Context-Position Attention (문맥-위치 분리)
│ └─ Image-Position Attention (이미지와 위치 결합)
│
├─ 학습 방법
│ ├─ 총 T! 중 K개 permutation 선정
│ └─ Flipped Permutation 활용해 안정성 확보
│
└─ Decoding 방식
├─ Autoregressive (순차적)
├─ Non-autoregressive (병렬적)
└─ Iterative Refinement (반복적 개선)728x90