1️⃣ 이미지 대 이미지
☑️ 이미지 대 이미지 변환
●이미지를 입력으로 받아 원하는 이미지를 출력하는 것
○최근에는 조건부 생성 모델을 이용하여 원하는 이미지를 생성하는 방법들이 주를 이룸

RBDN은 Generalized Deep Image to Image Regression을 위한 아키텍처로, 다음과 같은 기능을 제공
○조건부 GANs 이전에는 각 태스크별 모델과 손실 함수를 각각 정의해야 했음

☑️ 이미지 대 이미지 변환: 전통적 접근
●기존의 방식은 주어진 이미지를 회귀 모델을 통해 변환한 후, 타겟 이미지와 손실을 계산하여 개선하는 방식
●픽셀 요소별 L1 손실 혹은 L2 손실을 주로 활용

☑️ 이미지 대 이미지 변환: 전통적 접근의 한계
●변환된 이미지를 생성하는 것이 아니라 회귀 모델로 픽셀값을 예측하는 것이므로 흐릿한 이미지가 만들어짐
○평균 / 중간 값을 예측하는 한계가 있음

✅ Pix2pix (2017)
☑️ 쌍이 있는 이미지 변환 기술
●이미지 쌍이 있는 조건부 생성 모델 기반의 이미지 대 이미지 변환 프레임워크를 제안
○이미지 특성별로 회귀 모형을 만드는 것이 아닌, 생성 모델이 변환된 이미지를 생성하자!

☑️ 생성모델
● U-Net 기반의 생성 모델을 활용 – 인코더-디코더 구조에 건너뜀 연결 (Skip Connection)을 추가한 구조
○이미지 대 이미지 변환에서는 영상 세부 사항을 잘 유지하는 것이 중요

☑️ 판별 모델
● GANs의 판별 모델은 저해상도 모델에 더 적합하므로, 고해상도를 위한 패치 기반의 판별 모델이 필요
○ PatchGANs의 판별 모델 구조를 차용

☑️ 손실 함수
●조건부 GANs의 손실 함수 + 원본 이미지와의 유사성을 위한 L1 정규화 (Regularization) 항 추가

☑️ 결과 분석

☑️ 한계점
●데이터가 반드시 쌍으로 존재해야 하기에, 데이터를 확보하는 것이 어려움
○ ex) 같은 위치의 다른 계절, 같은 위치와 같은 자세의 얼룩말과 말 …

☑️ 쌍이 없는 이미지 변환 기술
● Pix2pix로부터 시작된 이미지 대 이미지 변환 기술들은 쌍이 존재하는 데이터셋으로만 구현이 가능
○현실의 문제에는 쌍이 없는 데이터셋이 훨씬 더 많음

✅ CycleGAN (2017)
☑️ 주요 아이디어
● Cycle Consistent: 상호 변환이 가능한 것; 한국어→영어 변환이 가능하다면, 영어→한국어 변환도 가능해야 함
●입력 이미지로 복원 가능한 정도까지만 이미지를 변환하도록 하여 원본 손실을 최소화

☑️ 손실 함수: 수식


☑️ 손실 함수: 직관적 이해

☑️ 결과분석

✅ BiCycleGAN (2017)
☑️ 하나의 입력, 다양한 출력
●하나의 영상이 다른 도메인에서 여러 양상으로 그려질 수 있음

✅ StarGAN (2017)
☑️ 여러 도메인간 변환
●세 개 이상의 도메인간 변환을 수행함

✅ InstaGAN (2019)
☑️ 여러 도메인간 변환
●모양이 매우 다른 객체간 변환을 가능하게 함

✅ LostGANs (2019)
☑️ 공간 구조로부터 이미지 생성
●다양한 이미지 생성 분야에서 좋은 성과가 있었지만, 공간 구조를 포함하는 형태의 연구는 많지 않았음
●공간 구조로부터 이미지를 생성해낸다는 것은 이미지 매핑 보존이 가능하다는 것
●이미지 매핑 보존을 기반으로 위치 이동 등 이미지 재구성까지 가능

✅ SPADE (GauGAN, 2019)
☑️ 의미 공간으로부터 이미지 생성
●의미 분할 정보를 이용하기 때문에 이미지 생성 단계에서 객체 추가, 변경 등이 가능
●같은 의미 영역에 대해 다양한 데이터를 생성해낼 수 있음

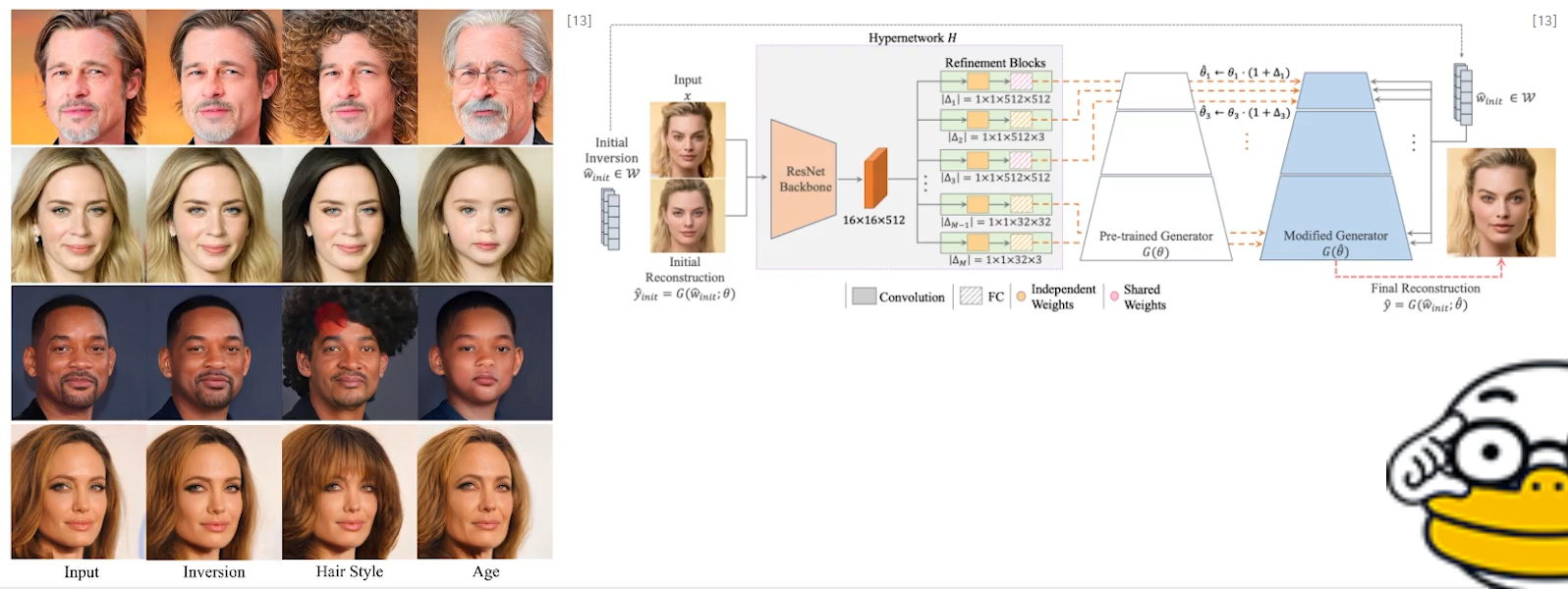
✅ HyperStyle (2022)
☑️ Pretrained GAN을 활용한 이미지 변환
●이미지만을 활용해 학습한 모델의 잠재 공간을 분석, 활용해 이미지 변환에 활용
2️⃣ 텍스트 대 이미지
✅ GAN-CLS (2016)
☑️ 텍스트 입력으로부터 이미지 생성
●문장은 단어보다 이미지를 풍부하고 유연하게 설명할 수 있음
○언어 입력으로부터 이미지를 생성할 수 있다면, 더 풍부한 이미지 생성 가능!

어려운만큼 그만큼 얻는 reward가 큼!
☑️ 텍스트 입력으로부터 이미지 생성: 어려움
●텍스트 생성은 순차적으로 단어를 생성하므로, 생성 시 더 많은 정보를 얻을 수 있음
●이미지는 한 번에 생성되므로 중요한 시각적 정보를 잘 인코딩하는 텍스트 특징 표현을 훈련해야 함

☑️ 손실 함수 (GAN-CLS)
●기존의 GANs 손실 함수는 실제 이미지 + 정확한 설명 (참) (정확한 레이블) , 생성 이미지 + 정확한 설명 (거짓)만 고려
●실제 이미지 + 부정확한 설명 (거짓), 생성된 이미지 + 정확한 설명 (거짓) 도 고려해야 함

☑️ 손실 함수: 개선된 버전 (GAN-INT-CLS)
●기존 방식: 훈련 텍스트와 훈련 이미지를 일대일로 매칭한 것을 훈련하기 때문에 테스트 시 성능 하락
(텍스트데이터가 부족할수도 있고 텍스트데이터의 이해도가 떨어질수 있음)
○텍스트 특징 벡터에 대한 보간법 (interpolation)을 이용하여 완화

☑️ 훈련: 의사 코드

☑️ 결과분석
●텍스트 정보를 입력으로 하여 이미지를 생성하는 데에 성공
●손실 함수에 텍스트와 보간법을 모두 적용하였을 때 가장 좋은 결과물을 생성함

✅ GigaGAN (2023)
☑️ GANs를 활용한 고해상도 텍스트 대 이미지 생성
●다른 생성 모델처럼 모델의 규모와 데이터를 매우 크게 만들어 학습, 텍스트 기반으로 고해상도 이미지를 생성함

☑️ Multi-stage Generation

☑️ 생성 모델 (generator부터)
1. 입력 받은 텍스트를 사전 훈련된 CLIP 인코더와 레이어 T 를 통해 임베딩
2. 스타일 네트워크 M 는 스타일 벡터 w 를 출력
3. 생성 네트워크 G̃ 는 텍스트 임베딩과 스타일을 입력으로 받아 이미지를 생성
☑️ 생성 모델 - Deep dive
●전역 정보를 통해 스타일을 생성하고, 지역 정보는 피라미드형 구조에 계속하여 조건 정보로 활용
● 이미지-이미지 셀프 어텐션, 이미지-텍스트 크로스 어텐션 활용
●텍스트에 따라 유동적으로 컨볼루션 커널을 생성하는 적응형 샘플 커널 선택 기술을 도입

☑️ 판별 모델
●생성 모델과 유사하게 축소되는 피라미드 형태로 구성 – 각 단계별로 독립적으로 판별 + 매 단계마다 텍스트 입력

줄어드는 형태
☑️ 결과 분석
●전역 정보를 활용하기 때문에 주어진 텍스트에 대한 보간이 잘 이루어짐
●생성 과정에서 지역 정보를 계속 조건으로 주기 때문에 독립적인 잠재 공간을 유지하며 스타일 변환이 가능

'03_Deep Leaning > Generation' 카테고리의 다른 글
| Generation_조건부 생성 모델 (0) | 2025.01.16 |
|---|---|
| Generation_ GANs적대적 생성 신경망(Generative Adversarial Networks) (1) | 2025.01.16 |
| Generation_벡터 양자화 변분 오토 인코더(VQVAE & VQVAE-2) (0) | 2025.01.16 |
| Generation_변분오토인코더(Variational Autoencoder, VAE) (0) | 2025.01.15 |
| Generation_오토인코더(Autoencoder) (0) | 2025.01.15 |